- +1
不吃蘑菇,不撿金幣,我用強化學(xué)習(xí)跑通29關(guān)馬里奧,刷新最佳戰(zhàn)績
機器之心報道
編輯:張倩、蛋醬
看了用強化學(xué)習(xí)訓(xùn)練的馬里奧,我才知道原來這個游戲的后幾關(guān)長這樣。

這款游戲承載了一代人的回憶,你還記不記得你玩到過第幾關(guān)?
其實,除了我們這些玩家之外,強化學(xué)習(xí)研究者也對這款游戲情有獨鐘。
最近,有人用 PPO 強化學(xué)習(xí)算法訓(xùn)練了一個超級馬里奧智能體,已經(jīng)打通了 29 關(guān)(總共 32 關(guān)),相關(guān)代碼也已開源。
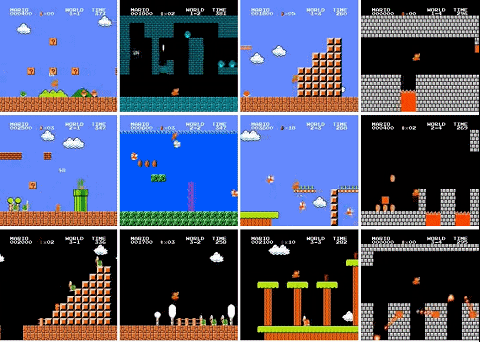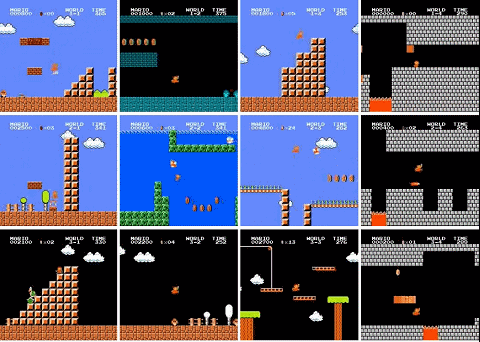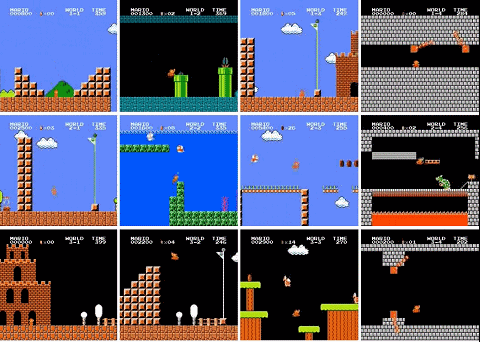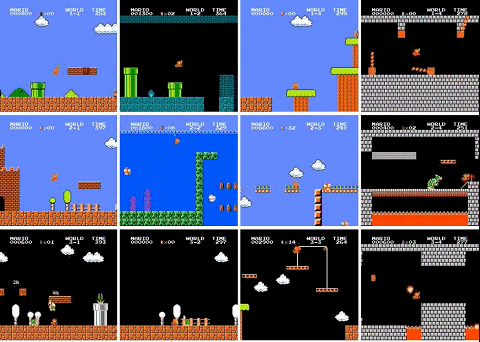

使用 PPO 訓(xùn)練的 OpenAI Five 是第一款在電競游戲中擊敗人類世界冠軍的 AI。2018 年 8 月,OpenAI Five 與 Ti8Dota2 世界冠軍 OG 戰(zhàn)隊展開了一場巔峰對決,最終 OpenAI Five 以 2:0 的比分輕松戰(zhàn)勝世界冠軍 OG。
此前,作者曾經(jīng)使用 A3C 算法訓(xùn)練過用于通關(guān)超級馬里奧兄弟的智能體。盡管智能體可以又快又好地完成游戲,但整體水平是有限的。無論經(jīng)過多少次微調(diào)和測試,使用 A3C 訓(xùn)練的智能體只能完成到第 9 關(guān)。同時作者也使用過 A2C 和 Rainbow 等算法進行訓(xùn)練,前者并未實現(xiàn)性能的明顯提升,后者更適用于隨機環(huán)境、游戲,比如乒乓球或太空侵略者。
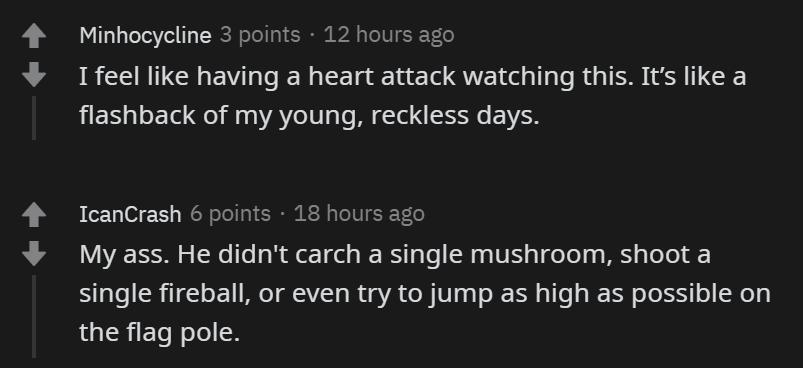
還有三關(guān)沒有過是怎么回事?作者解釋說,4-4、7-4 和 8-4 關(guān)的地圖都包含了一些謎題,智能體需要選擇正確的路徑才能繼續(xù)前進。如果選錯了路徑,就得重新把走過的路再走一遍,陷入死循環(huán)。所以智能體沒能通過這三關(guān)。
開源項目地址:https://github.com/uvipen/Super-mario-bros-PPO-pytorch
近端策略優(yōu)化算法
策略梯度法(Policy gradient methods)是近年來使用深度神經(jīng)網(wǎng)絡(luò)進行控制的突破基礎(chǔ),不管是視頻游戲、3D 移動還是圍棋控制,都是基于策略梯度法。但是通過策略梯度法獲得優(yōu)秀的結(jié)果是十分困難的,因為它對步長大小的選擇非常敏感。如果迭代步長太小,那么訓(xùn)練進展會非常慢,但如果迭代步長太大,那么信號將受到噪聲的強烈干擾,因此我們會看到性能的急劇降低。同時這種策略梯度法有非常低的樣本效率,它需要數(shù)百萬(或數(shù)十億)的時間步驟來學(xué)習(xí)一個簡單的任務(wù)。
2017 年,Open AI 的研究者為強化學(xué)習(xí)提出了一種新型策略梯度法,它可以通過與環(huán)境的交互而在抽樣數(shù)據(jù)中轉(zhuǎn)換,還能使用隨機梯度下降優(yōu)化一個「surrogate」目標(biāo)函數(shù)。標(biāo)準(zhǔn)策略梯度法為每一個數(shù)據(jù)樣本執(zhí)行一個梯度更新,因此研究者提出了一種新的目標(biāo)函數(shù),它可以在多個 epoch 中實現(xiàn)小批量(minibatch)更新。這種方法就是近端策略優(yōu)化(PPO)算法。
該算法從置信域策略優(yōu)化(TRPO)算法獲得了許多啟發(fā),但它更加地易于實現(xiàn)、廣泛和有更好的樣本復(fù)雜度(經(jīng)驗性)。經(jīng)過在一組基準(zhǔn)任務(wù)上的測試,包括模擬機器人移動和 Atari 游戲,PPO 算法展示出了比其他在線策略梯度法更優(yōu)秀的性能,該算法總體上在樣本復(fù)雜度、簡單性和實際時間(wall-time.)中有非常好的均衡。
近端策略優(yōu)化可以讓我們在復(fù)雜和具有挑戰(zhàn)性的環(huán)境中訓(xùn)練 AI 策略,先看這個 demo 視頻:
如上所示,其中智能體嘗試抵達粉紅色的目標(biāo)點,因此它需要學(xué)習(xí)怎樣走路、跑動和轉(zhuǎn)向等。同時該智能體不僅需要學(xué)會怎樣從小球的打擊中保持平衡(利用自身的動量),在被撞倒后還需要學(xué)會如何從草地上站起來。
PPO 方法有兩種主要的變體: PPO-Penalty 和 PPO-Clip。
PPO-Penalty 近似求解一個類似 TRPO 的被 KL - 散度約束的更新,但懲罰目標(biāo)函數(shù)中的 KL - 散度,而不是使其成為優(yōu)化問題的硬約束, 并在訓(xùn)練過程中自動調(diào)整懲罰系數(shù),從而適當(dāng)?shù)卣{(diào)整其大小。
PPO-Clip 在目標(biāo)中沒有 KL 散度項,也沒有約束。取而代之的是在目標(biāo)函數(shù)上進行專門裁剪 (clip), 以消除新策略遠離舊策略的激勵 (incentives)。
關(guān)于該算法的更多信息可以參考原論文。

網(wǎng)友:馬里奧的奔跑,是我放蕩不羈的青春
項目作者用 Pytorch 實現(xiàn)的《超級馬里奧》demo 在 reddit 上引起了上千人圍觀,作者也現(xiàn)身評論區(qū)答疑解惑。
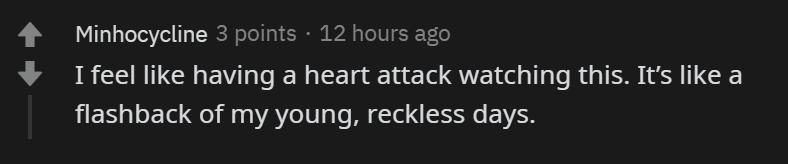
有人說,「他跑得那么快、那么不管不顧,看得我捏了一把汗。」


機器之心聯(lián)合曠視科技開設(shè)線上公開課:零基礎(chǔ)入門曠視天元MegEngine,通過6次課程幫助開發(fā)者入門深度學(xué)習(xí)開發(fā)。
8月4日,曠視研究院深度學(xué)習(xí)框架研究員劉清一將帶來等二課,主要介紹數(shù)據(jù)預(yù)處理、模型搭建與調(diào)參等相關(guān)概念。歡迎大家入群學(xué)習(xí)。
? THE END
轉(zhuǎn)載請聯(lián)系本公眾號獲得授權(quán)
投稿或?qū)で髨蟮溃篶ontent@jiqizhixin.com
原標(biāo)題:《不吃蘑菇,不撿金幣,我用強化學(xué)習(xí)跑通29關(guān)馬里奧,刷新最佳戰(zhàn)績》
本文為澎湃號作者或機構(gòu)在澎湃新聞上傳并發(fā)布,僅代表該作者或機構(gòu)觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發(fā)布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯(lián)網(wǎng)新聞信息服務(wù)許可證:31120170006
增值電信業(yè)務(wù)經(jīng)營許可證:滬B2-2017116
? 2014-2025 上海東方報業(yè)有限公司

