- +1
AI詩人的十四行詩,能賽過莎翁的嗎?
原創(chuàng) J.L T.C T.B&A.H 神經(jīng)現(xiàn)實(shí) 來自專輯深度 | Deep-diving

這是莎士比亞第18首十四行詩中的一個(gè)詩節(jié):

thou art more lovely and more temperate:
rough winds do shake the darling buds of May,
and summer's lease hath all too short a date
我可能把你和夏天相比擬?
你比夏天更可愛更溫和:
狂風(fēng)會(huì)把五月的花苞吹落地,
夏天也嫌太短促,匆匆而過*
*譯者注
本文中出現(xiàn)的莎士比亞十四行詩中文譯作除非特別說明,均為梁實(shí)秋譯本。

這是由人工智能程序Deep-speare創(chuàng)作的十四行詩:
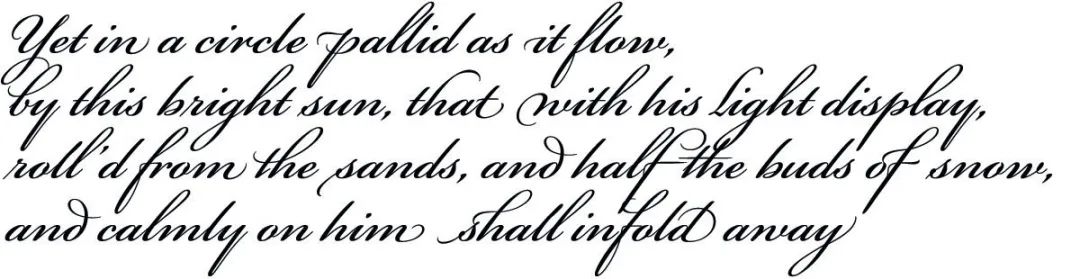
by this bright sun, that with his light display,
roll'd from the sands, and half the buds of snow,
and calmly on him shall infold away
它流淌,在蒼白的旋渦中
路過明媚的陽光,他的光輝閃耀
終于滾落在細(xì)沙上,雪般的花蕾含苞待放
輕覆其身,悄然而逝
仔細(xì)閱讀Deep-speare寫的詩,你可能會(huì)察覺到一絲荒謬,不過它倒確實(shí)遵循章法,用英文老師的話來說就是,乍看之下這首詩歌每一行的節(jié)奏、韻律和基本語法都還挺像那么一回事。正如我們的研究團(tuán)隊(duì)發(fā)現(xiàn)的那樣,當(dāng)我們向全世界展示AI創(chuàng)作的詩歌時(shí),不少人都被糊弄過去了——大多數(shù)讀者無法區(qū)分開AI生成的詩和人類作者寫出的作品。
我們的團(tuán)隊(duì)由三位機(jī)器學(xué)習(xí)研究人員和一名文學(xué)學(xué)者組成,我們使用古騰堡工程在線圖書館(Project Gutenberg)收錄的2700首十四行詩來訓(xùn)練AI詩人。我們的AI詩人利用被稱為深度學(xué)習(xí)的AI方法,對(duì)訓(xùn)練數(shù)據(jù)庫中的詩歌進(jìn)行挖掘,不斷地“冥思苦想”出與樣本匹配的詩句,自己學(xué)會(huì)作詩的。我們并沒有像以往類似的項(xiàng)目一樣,給AI詩人輸入韻律、發(fā)音方面的字典等資源,然而,Deep-speare靠著摸索,自己學(xué)會(huì)了十四行詩寫作的三大要素:節(jié)奏、韻律,和自然語言的基本原理(即如何將詞匯流暢地銜接在一起)。
*譯者注
古騰堡工程(Project Gutenberg),是一項(xiàng)志愿工作,致力于將文化作品的數(shù)字化和歸檔,以“鼓勵(lì)創(chuàng)作和發(fā)行電子書”為其宗旨。該工程肇始于1971年,是最早的數(shù)字圖書館。截至2012年7月,古騰堡工程聲稱超過40,000件館藏。
我們的目標(biāo)是探索深度學(xué)習(xí)在生成自然語言上能做到何種程度,以及如何充分利用詩歌的有趣特質(zhì)。尤其是像十四行詩這樣的詩歌,其節(jié)奏和韻律有著刻板和規(guī)整的模式,我們想知道我們是否可以通過設(shè)計(jì)系統(tǒng)體系,讓Deep-speare自主學(xué)習(xí)此類模式。
我們的努力離不開計(jì)算創(chuàng)造力領(lǐng)域的蓬勃發(fā)展。一幅由AI創(chuàng)作出的肖像畫曾在紐約佳士得(Christie’s)拍賣行以43.2萬美元的價(jià)格成交;AI作曲項(xiàng)目DeepBach創(chuàng)作的巴赫風(fēng)格音樂作品足以讓人信以為真;而在雕塑和舞蹈的領(lǐng)域,也能看見AI的身影。除此之外,在語言和文學(xué)方面,來自O(shè)penAI實(shí)驗(yàn)室的GPT-2文本生成系統(tǒng)憑實(shí)力證明了人工智能可以僅通過開頭句,就能生產(chǎn)出相當(dāng)流暢的文本段落。
*譯者注
計(jì)算創(chuàng)造力(computatinal creativity, 也稱為人工智能創(chuàng)造力,機(jī)器創(chuàng)造力或創(chuàng)造力計(jì)算學(xué))是一項(xiàng)跨學(xué)科的研究領(lǐng)域,位于人工智能,認(rèn)知心理學(xué),哲學(xué)和藝術(shù)領(lǐng)域的交匯處。
在過去的十年里,正是深度學(xué)習(xí)的蓬勃發(fā)展才使得這些關(guān)于計(jì)算創(chuàng)造力的實(shí)驗(yàn)成為可能。深度學(xué)習(xí)具有創(chuàng)作追求的幾個(gè)關(guān)鍵優(yōu)勢:對(duì)初學(xué)者來說,它非常靈活,而且也能相對(duì)容易地訓(xùn)練出能執(zhí)行各種任務(wù)的深度學(xué)習(xí)系統(tǒng)(我們稱之為模型)。這些模型擅長發(fā)現(xiàn)模式,并從中進(jìn)行總結(jié)歸納——有時(shí)候甚至?xí)a(chǎn)生令人驚奇的結(jié)果,而這種優(yōu)勢也被稱為“偶發(fā)創(chuàng)造力”。同時(shí),深度學(xué)習(xí)算法內(nèi)在因素的隨機(jī)性會(huì)導(dǎo)致輸出結(jié)果的千變?nèi)f化。這種結(jié)果上的千變?nèi)f化如果能夠被人類協(xié)作者耐心地篩出,那么這種可變性將非常適合創(chuàng)造性應(yīng)用。不僅如此,深度算法還能相對(duì)容易地建立可處理不同類型數(shù)據(jù)的模型,包括文本、語音、文字和視頻等。
一首詩是如何被寫出來的?
關(guān)于自然語言處理模型
十四行詩最主要有兩個(gè)特點(diǎn):14行的長度,和由兩部分組成的“論證”結(jié)構(gòu)。后者指的是詩人一般會(huì)在詩歌的前半部分提出一個(gè)問題,然后用結(jié)尾的部分來解答這個(gè)疑惑。在十六世紀(jì),英國詩人采用“五步抑揚(yáng)格”(iambia pentameter)的節(jié)奏方式來創(chuàng)作詩歌,即一行詩歌擁有10個(gè)音節(jié)(5個(gè)音步)的輕重音節(jié)奏。通常,一首十四行詩由三個(gè)用來提出“問題”的四行詩(quatrain)和末尾的對(duì)偶句(couplet)構(gòu)成,詩歌的韻律常為「ABAB CDCD EFEF GG」。在莎士比亞手里,此種韻律形式使用到了最純熟的地步,以至于今天我們都稱其為“莎士比亞體之十四行詩”。
在Deep-speare項(xiàng)目組中,我們?cè)噲D生成莎士比亞十四行詩前半部分的“發(fā)問”段落中的一段四行詩。因此,相比于簡單復(fù)制詩歌的十四行形式或者結(jié)尾的兩行“論證”的詩句,我們更專注于生成遵循“五步抑揚(yáng)格”和韻律的文本。我們也許會(huì)在未來的某天繼續(xù)攻克這個(gè)更難的挑戰(zhàn),但目前我們更需要證明的是AI詩人具備產(chǎn)生一段單獨(dú)的四行詩的能力。
Deep-speare采用了三種自然語言處理模型進(jìn)行創(chuàng)作,它們分別是通過評(píng)估備選單詞的概率選擇合適單詞的語言模型、評(píng)估每行詩歌的節(jié)奏的節(jié)奏模型,以及確保每行詩歌都遵循韻律的韻律模型。
AI詩人會(huì)隨機(jī)選擇一種經(jīng)典韻律來創(chuàng)作詩節(jié)。比如下圖這個(gè)例子,它就采用了“ABBA”的押韻方式,即在一個(gè)四行的詩節(jié)當(dāng)中,首尾兩行押韻,中間兩行押韻。在掌握這個(gè)模版之后,它以一個(gè)令人驚訝的方式開始生成這首詩歌——從最后一行的最后一個(gè)單詞開始,從右到左生成符合規(guī)律的文本。

2. 以退為進(jìn),AI詩人通過對(duì)每個(gè)詞倒推來進(jìn)行文本生成,而每一個(gè)候選單詞的概率得分顯示了單詞之間相鄰關(guān)系和出現(xiàn)在同一句子中的概率(如下圖所示)。


for just but tempteth me to stay and pray
a cry: if it will drag me, find no way
怎么忍心看他愁云慘霧傷悲
耿耿于懷的我駐足祈禱安慰
只怕眼淚來襲 我無法應(yīng)對(duì)
4. 以退為進(jìn)、從后往前,AI詩人不斷重復(fù)這樣的步驟,以從最后一句到第一句的方式,繼續(xù)生成文本。
5. 在尋找合適的單詞來給第二句和第一句詩結(jié)尾時(shí)(“pray” 和 “state”),AI詩人會(huì)給候選單詞的“押韻度”評(píng)分,找到與“way”和 “wait”押韻的辭藻。
總的來說,我們的系統(tǒng)由三個(gè)部分組成:一個(gè)學(xué)會(huì)了“五步抑揚(yáng)格”的節(jié)奏模型,一個(gè)學(xué)會(huì)了詞匯押韻的模型,以及一個(gè)學(xué)會(huì)了詞與詞之間的經(jīng)典搭配的語言模型,其中語言模型是能夠逐字生成十四行詩的最主要部分。
語言模型會(huì)通過概率評(píng)分的方法,對(duì)任意語句進(jìn)行排名,判斷哪些語句在某種語言之中是正確的 (在我們的例子中是英語)。經(jīng)過適當(dāng)訓(xùn)練的語言模型會(huì)賦予流利的句子較高的概率分,給無意義的句子較低的概率分。考慮到語言生產(chǎn)和理解方式一般是逐詞進(jìn)行,這個(gè)原理實(shí)際上允許我們把更復(fù)雜的、句子層面上的問題分解成單詞層面的簡單問題。因此,語言模型的工作就是通過部分句子預(yù)測下一個(gè)單詞是什么。為了進(jìn)行這種預(yù)測,模型會(huì)查找所有可能的單詞并給予它們概率分?jǐn)?shù),而這些分?jǐn)?shù)取決于目前句子中已有的詞匯。
語料庫
通常,自然語言模型會(huì)通過語料庫的單詞和句子判斷文本的出現(xiàn)概率,而語料庫的內(nèi)容可以來自維基百科詞條,Reddit中的討論,或者專門用于訓(xùn)練語言處理的語料庫。從文字庫中,人工智能可以學(xué)習(xí)哪些單詞是最常一起出現(xiàn)的。而在我們的Deep-speare項(xiàng)目中,AI詩人先是從在線圖書館Project Gutenberg收錄的全部詩歌中學(xué)會(huì)了語言運(yùn)用的基本課程,然后再通過包含了36.7萬個(gè)單詞的2700首莎士比亞十四行詩來進(jìn)一步打磨它的十四行詩寫作能力。
人們對(duì)下一個(gè)單詞的“驚奇”程度可以被用于衡量一個(gè)語言模型的質(zhì)量。如果下一個(gè)單詞被賦予了很高的概率分?jǐn)?shù),這說明這個(gè)單詞的出現(xiàn)比較符合規(guī)律,所以并不會(huì)讓人感到驚訝;但如果被賦予了很低的概率分?jǐn)?shù),那么人們?cè)谧x到這個(gè)單詞的時(shí)候,會(huì)感到非常不自然。這種驚奇程度在訓(xùn)練模型的過程中被當(dāng)成重要的信號(hào)。因此,當(dāng)我們每次都通過大量文本來處理每一個(gè)詞匯,而且模型不會(huì)對(duì)連在一起的詞匯感到驚訝,那么我們便可以認(rèn)為,這個(gè)模型已經(jīng)很大程度上掌握了語言的復(fù)雜性了。而這就包括能夠正確運(yùn)用“San -Francisco”這樣由多單詞構(gòu)成的詞組而不拆開它們、遵循一定句式和語法結(jié)構(gòu),以及判斷較為復(fù)雜的語義和邏輯信息(例如,咖啡常常用“濃”和“淡”,而不會(huì)用“強(qiáng)壯”和“輕便”來修飾)等原則。
一旦語言模型被訓(xùn)練好了,無中生有地生成單句或多條詩句就不再是難事了。
接下來,我們讓節(jié)奏模型遵守每行詩歌要有10個(gè)以輕音重音的模式結(jié)合音節(jié)的規(guī)律,然后,它會(huì)檢查每個(gè)單詞的字母和句子的標(biāo)點(diǎn)符號(hào),通過字母決定音節(jié)該如何分配,哪一個(gè)音節(jié)要?dú)w類為重音。比如“summer”一詞有兩個(gè)音節(jié),“sum”是重音,“mer”是輕音,當(dāng)Deep-speare在寫四行詩時(shí),語言模型會(huì)生成候選詩句,節(jié)奏模型會(huì)從中選出符合“五步抑揚(yáng)格”的一句,然后再重復(fù)這一過程,生成下一行詩句。
韻律模型也是從過去的十四行詩集中含英咀華學(xué)會(huì)的,但它只會(huì)看每行最后一個(gè)單詞的字母。在訓(xùn)練過程中,我們告訴模型,在四行詩中的每句詩的最后一個(gè)詞都需要押韻,然后我們讓它找出那些詞中最相似的詞,越是相似的單詞,就越有可能押韻。以莎士比亞的詩歌為例子,“day”和“May”的押韻分?jǐn)?shù)很高,“temperate”和“date”也是如此。
一旦Deep-speare被訓(xùn)練好并準(zhǔn)備創(chuàng)作,我們會(huì)給它提供莎士比亞十四行詩中三個(gè)最經(jīng)典的韻律模版來從中選擇:AABB, ABBA, ABAB。在寫作過程中,語言模型會(huì)先隨機(jī)選取其中一個(gè)模板,再逐詞地產(chǎn)生詩句,當(dāng)寫到了應(yīng)該押韻的單詞時(shí),它會(huì)為押韻模型提供多個(gè)候選單詞。
下面有兩個(gè)例子可以很好地解釋Deep-speare生產(chǎn)文本的過程。第一篇文本是由稍微訓(xùn)練過的模型所創(chuàng)作的,它初步掌握了韻律,但尚未找到節(jié)奏,且詩歌讀起來并不是很通順。
by complex grief’s petty nurse. had wise upon
along
came all me’s beauty, except a nymph of song
to be in the prospect, he th of forms i join
and long in the hears and must can god to run
由復(fù)雜的悲傷的美麗小護(hù)士
來吧我所有的美麗,除了一首歌
在光明的未來里,我加入的形式
長時(shí)間聆聽,必須讓上帝奔跑
第二篇文本則是由訓(xùn)練臻于完善的模型生成的,相較第一篇可以看出,它取得了很大的進(jìn)步。它ABBA的韻律是正確的,遵循了“五步抑揚(yáng)格”,語言不僅流暢,還頗有詩意!
shall i behold him in his cloudy state
for just but tempteth me to stop and pray
a cry: if it will drag me, find no way
from pardon to him, who will stand and wait
怎么忍心看他愁云慘霧傷悲
耿耿于懷的我駐足祈禱安慰
只怕眼淚,來襲我無法應(yīng)對(duì)
誰得寬恕,誰又將駐足等待
AI詩人寫的詩到底好不好?
在檢驗(yàn)Deep-speare的輸出結(jié)果時(shí),我們首先要確保它沒有復(fù)制語料庫里的原句。我們發(fā)現(xiàn),它作品中的詩句并未和訓(xùn)練數(shù)據(jù)有很大重疊,因此,我們相信AI詩人不是單靠復(fù)制粘貼產(chǎn)生作品的,它的詩歌可以說都是原創(chuàng)的。
不過 ,原創(chuàng)并不是質(zhì)量好的代名詞,為了檢驗(yàn)作品質(zhì)量,我們請(qǐng)了人類評(píng)委進(jìn)行分析,他們來自兩個(gè)不同的背景。第一組評(píng)委是亞馬遜Mechanical Turk平臺(tái)雇傭的眾包工人,他們只會(huì)基礎(chǔ)的英語,沒有詩歌方面的專業(yè)知識(shí)。我們向他們同時(shí)展示AI詩人和人類詩人寫的十四行詩,并讓他們指出哪一首是人類寫的。

但第一次的檢驗(yàn)結(jié)果令我們感到大失所望,因?yàn)楣と藗兛梢越跬昝乐赋瞿氖资侨祟愒姼瑁】瓷先C(jī)器學(xué)習(xí)的結(jié)果顯然不符合人們的鑒賞標(biāo)準(zhǔn)。那這么一來,我們AI詩人的研究之路是不是就到此為止了?
接著,我們思考了這近乎百分百識(shí)別率背后的原因或許是——第一組評(píng)委作弊了。我們的語料庫來自古騰堡工程在線圖書館,因而文本都是可以被搜到的,于是我們?cè)谙耄瑫?huì)不會(huì)是他們復(fù)制了待判斷的詩歌,再到網(wǎng)上去搜是誰寫的?抱著這種猜測,我們的研究人員也依葫蘆畫瓢,測試了一番,事實(shí)證明我們是對(duì)的——人類詩歌作品總是可以搜到一些結(jié)果,達(dá)到百分百鑒別率是輕而易舉的事情。
為了防止評(píng)委們耍小技巧作弊,我們把所有的待鑒別詩歌都轉(zhuǎn)換為圖像,再讓他們指出哪首是人類詩歌作品。看!這次他們的正確率從近乎百分百下降到了百分之五十,這說明他們無法準(zhǔn)確地區(qū)分人類和機(jī)器人的詩歌作品。盡管我們還是無法阻止所有人不去手動(dòng)輸入詩歌再谷歌一下結(jié)果,但手動(dòng)查找確實(shí)需要花費(fèi)不少時(shí)間。總的來說,這次正確率的下降說明了AI詩人的作品在某種程度上,確實(shí)可以以假亂真。
我們的第二位評(píng)委是多倫多大學(xué)文學(xué)助理教授亞當(dāng)·哈蒙德(Adam Hammond)。與第一組評(píng)委的測試過程不同,第二次質(zhì)量檢驗(yàn)不再是猜測游戲。相反,哈蒙德將會(huì)收到混合著人工和機(jī)器創(chuàng)作的詩歌,并從韻律、節(jié)奏、可讀性和情感影響力這四個(gè)維度對(duì)它們進(jìn)行打分。
他給了Deep-speare十四行詩很高的韻律分和節(jié)奏分,實(shí)際上,與人類寫作的十四行詩相比,它們?cè)陧嵚珊凸?jié)奏上的評(píng)分更高。對(duì)這個(gè)結(jié)果,哈蒙德也并不感到驚訝,他認(rèn)為人類詩人經(jīng)常打破規(guī)律來取得一些詩歌效果。反倒是在可讀性和情感影響力上,AI詩人則明顯遜色了不少,文學(xué)專家可以輕易通過這兩個(gè)方面指出哪首是機(jī)器的創(chuàng)作。
AI寫詩的能力是幻想?
Deep-speare項(xiàng)目最有趣的地方之一是它造成的轟動(dòng)。我們?cè)?018年計(jì)算語言學(xué)學(xué)術(shù)會(huì)議上做完報(bào)告之后,世界各地的新聞媒體報(bào)道了這個(gè)成果。很多文章都引用了以下的詩節(jié),以證明AI詩人Deep-speare能夠創(chuàng)造像人類創(chuàng)造的詩歌:
With joyous gambols gay and still array,
no longer when he ’twas, while in his day
at first to pass in all delightful ways
around him, charming, and of all his days.
當(dāng)哈蒙德在BBC廣播電臺(tái)接受采訪的時(shí)候,主持人朗讀了這個(gè)段落并問他的看法,哈蒙德則反問主持人是否有注意到詩歌中明顯的語法錯(cuò)誤“he ’twas”來作為“he it was”(不成立的表達(dá))的縮寫,主持人表示她并沒注意到。
社會(huì)科學(xué)家雪莉·特克爾(Sherry Turkle)把人們忽視人工智能的明顯錯(cuò)誤,卻依然感慨其成就的現(xiàn)象稱為“伊莉莎效應(yīng)”(the Eliza effect)。換句話說,人們可以過度解讀機(jī)器產(chǎn)生的結(jié)果,甚至讀出來原本不存在的意義。這個(gè)現(xiàn)象最早可以追溯到十九世紀(jì)六十年代,在麻省理工大學(xué),計(jì)算機(jī)科學(xué)家約瑟夫·維森鮑姆(Joseph Weizenbaum)開發(fā)了第一個(gè)聊天機(jī)器人伊莉莎(Eliza),它會(huì)模仿心理治療師的說話方式。盡管這個(gè)程序相當(dāng)粗糙,還有很大的局限性,但維森鮑姆驚訝地發(fā)現(xiàn)用戶輕易地就被機(jī)器人“欺騙”了。在七十年代,作為維森鮑姆同事的特克爾發(fā)現(xiàn),甚至那些明知伊莉莎程序有缺陷的研究生也會(huì)向機(jī)器拋出問題,并期待它以近似正常人類的方式去回答。
特克爾把伊莉莎效應(yīng)稱為“數(shù)字幻想中的人類同謀”,而這看起來也可以解答人們對(duì)Deep-speare詩歌作品的贊嘆反應(yīng)。公眾太希望這些十四行詩可以用于證明人工智能的力量,以至于忽略了那些與之相悖的證據(jù)。
這種蓄意的誤解可能會(huì)對(duì)AI詩人真正的能力發(fā)展造成阻礙。我們還在持續(xù)進(jìn)行AI詩人的項(xiàng)目,目標(biāo)之一就是提升我們AI詩人作品的可讀性和情感影響力。而要想提升整體的流暢度,其中一個(gè)策略是利用大范圍的語料庫(例如整個(gè)維基百科)去“預(yù)訓(xùn)練”語言模型,讓它可以在一段較長的敘述中更好掌握詞匯出現(xiàn)的規(guī)律。在這個(gè)基礎(chǔ)上,我們?cè)龠M(jìn)一步對(duì)它進(jìn)行十四行詩文本生成的訓(xùn)練。

我們同樣也在思考,人類詩人是如何創(chuàng)作詩歌的:他們總不會(huì)在桌子旁正襟危坐,思考著“我第一個(gè)單詞應(yīng)該是什么”,然后冥思苦想,思考下一個(gè)單詞該接什么好。相反,他們都是心中先構(gòu)思出一個(gè)主題或者一段故事,再通過單詞和句子表達(dá)所思所想。其實(shí)在Deep-speare項(xiàng)目中,我們已經(jīng)做到了讓AI詩人根據(jù)給定的主題來生成相關(guān)的文本,比如讓它創(chuàng)作主題是“愛”或“失去”的詩句。讓機(jī)器按照一定的主題,也許會(huì)提升詩歌的流暢度,但與此同時(shí),它的詞匯選擇將不會(huì)那么豐富,因?yàn)樗傄葘W(xué)習(xí)哪些詞匯符合某些主題。之后,我們計(jì)劃使用更多分層的語言模型進(jìn)行實(shí)驗(yàn),先為詩歌生成高級(jí)敘事,再在這個(gè)框架下生成每一個(gè)詞匯——就如人類思考的路徑一樣。
確實(shí),這是一個(gè)宏偉的目標(biāo),但我們希望Deep-speare項(xiàng)目可以在將來達(dá)到這樣的標(biāo)準(zhǔn),就算不能變成真正的AI莎士比亞,那也要盡力成為莎士比亞在《情女怨》曾描述過的樣子:
He had the dialect and different skill,
Catching all passions in his craft of will.
“他有豐富的詞匯和無數(shù)技巧,
隨心所欲讓所有人為之傾倒。”
作者:Jey Han Lau, Trevor Cohn, Timothy Baldwin and Adam Hammond | 封面:Karolis Strautniekas
譯者:Yingying | 審校:里昂
排版:濟(jì)一
原文:
https://spectrum.ieee.org/artificial-intelligence/machine-learning/this-ai-poet-mastered-rhythm-rhyme-and-natural-language-to-write-like-shakespeare
原標(biāo)題:《AI詩人的十四行詩,能賽過莎翁的嗎?》
本文為澎湃號(hào)作者或機(jī)構(gòu)在澎湃新聞上傳并發(fā)布,僅代表該作者或機(jī)構(gòu)觀點(diǎn),不代表澎湃新聞的觀點(diǎn)或立場,澎湃新聞僅提供信息發(fā)布平臺(tái)。申請(qǐng)澎湃號(hào)請(qǐng)用電腦訪問http://renzheng.thepaper.cn。


- 澎湃新聞微博
- 澎湃新聞公眾號(hào)

- 澎湃新聞抖音號(hào)
- IP SHANGHAI
- SIXTH TONE
- 報(bào)料熱線: 021-962866
- 報(bào)料郵箱: news@thepaper.cn
滬公網(wǎng)安備31010602000299號(hào)
互聯(lián)網(wǎng)新聞信息服務(wù)許可證:31120170006
增值電信業(yè)務(wù)經(jīng)營許可證:滬B2-2017116
? 2014-2025 上海東方報(bào)業(yè)有限公司

