- +1
谷歌大腦新研究:單一任務的強化學習遇瓶頸?
原創 關注前沿科技 量子位
魚羊 發自 凹非寺
量子位 報道 | 公眾號 QbitAI
雅達利游戲,又被推上了強化學習基礎問題研究的舞臺。
來自谷歌大腦的最新研究提出,強化學習雖好,效率卻很低下,這是為啥呢?
——因為AI遭遇了「災難性遺忘」!
所謂災難性遺忘,是機器學習中一種常見的現象。在深度神經網絡學習不同任務的時候,相關權重的快速變化會損害先前任務的表現。
而現在,這項圖靈獎得主Bengio參與的研究證明,在街機學習環境(ALE)的單個任務中,AI也遇到了災難性遺忘的問題。
研究人員還發現,在他們提出的Memento observation中,在原始智能體遭遇瓶頸的時候,換上一只相同架構的智能體接著訓練,就能取得新的突破。
單一游戲中的「災難性干擾」
在街機學習環境(Arcade Learning Environment,ALE)中,多任務研究通常基于一個假設:一項任務對應一個游戲,多任務學習對應多個游戲或不同的游戲模式。
研究人員對這一假設產生了質疑。
單一游戲中,是否存在復合的學習目標?也就是說,是否存在這樣一種干擾,讓AI覺得它既要蹲著又要往前跑?
來自谷歌大腦的研究團隊挑選了「蒙特祖瑪的復仇」作為研究場景。
「蒙特祖瑪的復仇」被認為是雅達利游戲中最難的游戲之一,獎勵稀疏,目標結構復雜。
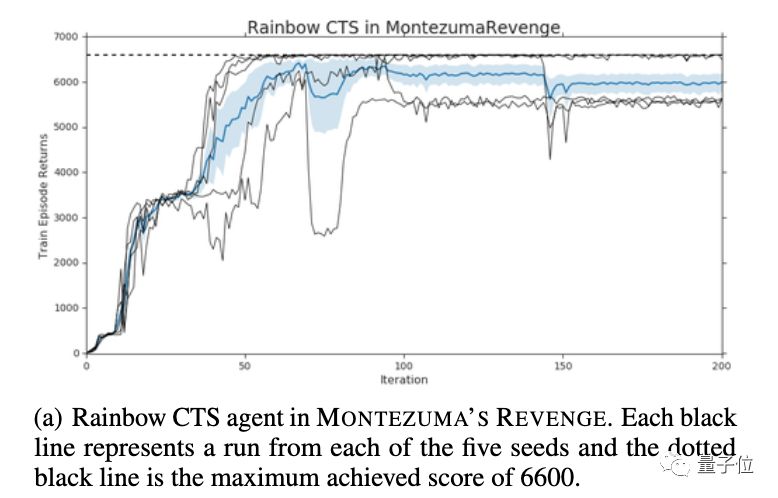
如此再重置一次,AI的最高分就來到了14500分。
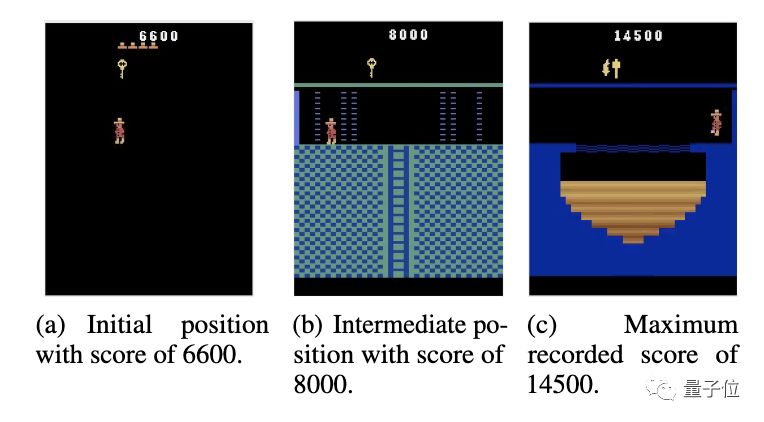
研究人員給這種現象起了一個名字,叫Memento observation。
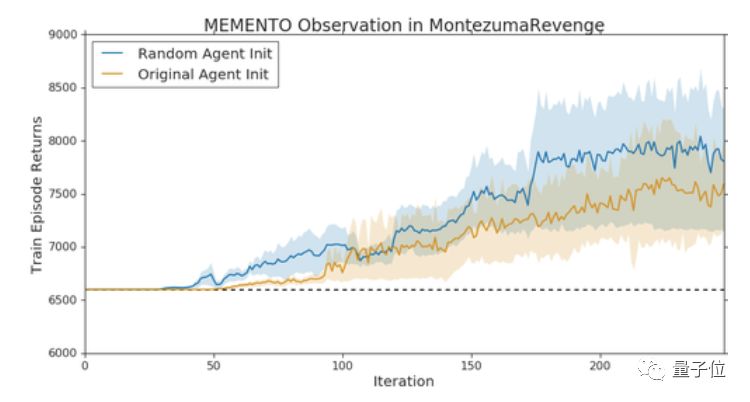
原因是,智能體無法在不降低第一階段游戲性能的情況下,集成新階段游戲的信息,和在新區域中學習值函數。
也就是說,在稀疏獎勵信號環境中,通過新的獎勵集成的知識,可能會干擾到過去掌握的策略。
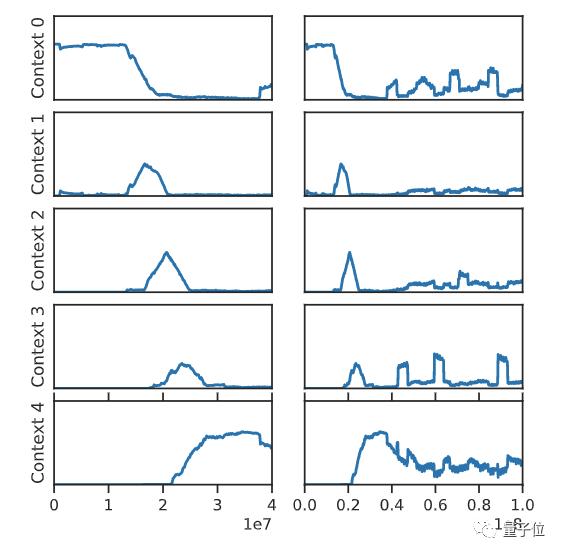
在訓練早期(左列),因為尚未發現之后的環節,智能體總是在第一階段進行獨立訓練。到了訓練中期,智能體的訓練開始結合上下文,這就可能會導致干擾。而到了后期,就只會在最后一個階段對智能體進行訓練,這就會導致災難性遺忘。
并且,這種現象廣泛適用。
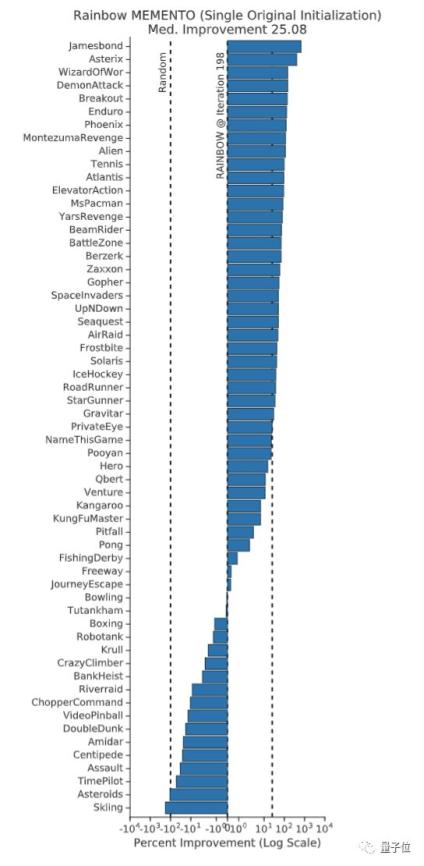
在整個ALE中,Rainbow Memento智能體在75%的游戲中表現有所提升,其中性能提升的中位數是25%。
這項研究證明,在深度強化學習中,單個游戲中的AI無法持續學習,是因為存在「災難性干擾」。
并且,這一發現還表明,先前對于「任務」構成的理解可能是存在誤導的。研究人員認為,理清這些問題,將對強化學習的許多基礎問題產生深遠影響。
傳送門
論文地址:
https://arxiv.org/abs/2002.12499
GitHub:
https://github.com/google-research/google-research/tree/master/memento
作者系網易新聞·網易號“各有態度”簽約作者
— 完 —
原標題:《谷歌大腦新研究:單一任務的強化學習遇瓶頸?是「災難性遺忘」的鍋!圖靈獎得主Bengio參與》
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

