- +1
這家巨頭全球月活超30億,為掩飾AI落后,大模型公然刷分造假!
1000萬上下文?2萬億參數?MoE混合架構,原生多模態。清明假期,你是否也被Meta這波Llama 4系列模型發布后,各種酷炫數據和名詞炸醒?
曾經的開源領袖,實際已經被DeepSeek搶了各種風頭。在扎克伯格下死命令,4月初必須發布新版本大模型的強大壓力下,Llama一切動作已經變形。原本使命是超越GPT和Claude等閉源模型,吊打一切的存在,然后呢?實現了嗎?

Llama 4系列模型發布:
Llama 4 Scout(小)
單張H100 GPU可運行,適合本地部署,支持1000萬token上下文,這是行業最牛成績。
Llama 4 Maverick(中)
總參數高達4000億,但推理時僅激活部分專家,效率更高。
多模態性能超越GPT-4o,在ChartQA、DocVQA等基準測試中領先,編程能力媲美DeepSeek v3,但參數僅一半。
Llama 4 Behemoth(大,預覽版)
Meta 2萬億參數巨獸,仍在訓練中。
超大參數,據說STEM任務超越GPT-4.5、Claude3.7等。
將作為“教師模型”,用于蒸餾優化更小的Llama 4模型。
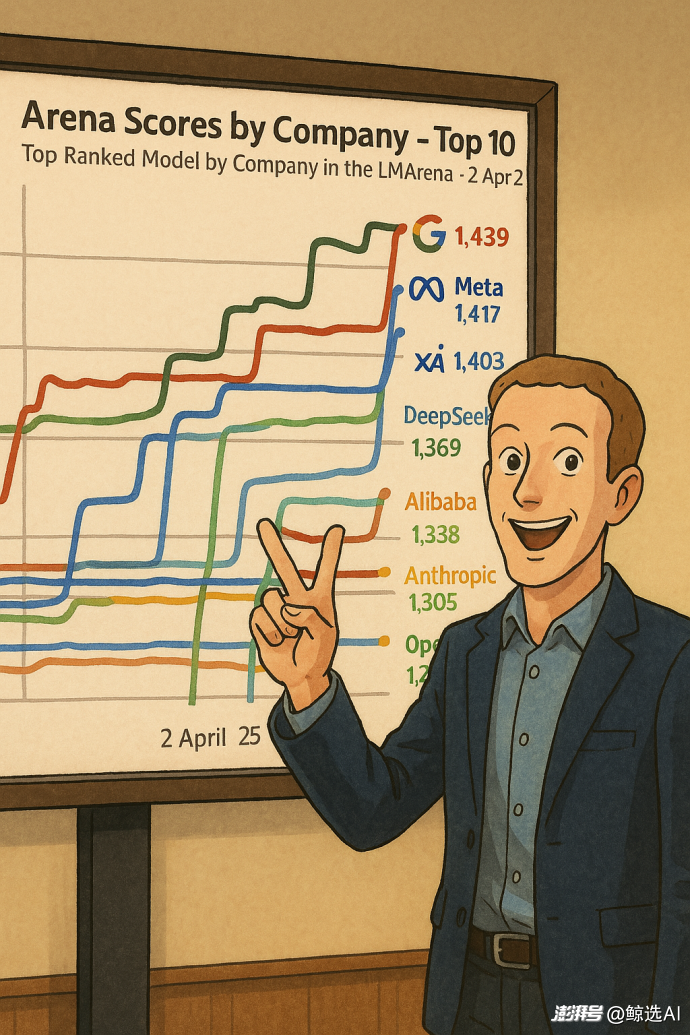
測評分數高居全球第二
Llama 4 Maverick 目前在LM Arena 排行榜上排名第二,僅次于 Gemini 2.5 Pro。
而且具備原生多模態能力:Llama 4采用了早期融合(Early Fusion)技術,可以用海量的無標簽文本、圖片和視頻數據一起來預訓練模型。

超長上下文:
Scout 版本支持1000萬 tokens(約15000頁文本!),醫學、科研、代碼分析等超長文檔處理能力直接拉滿。
在其他大模型僅有200萬 tokens上下長度時,小扎掏出了大炸雷,不想和大家閑聊。

幾個核心技術
MoE架構效率炸裂:
Llama 4開始轉向采用混合專家模型(MoE),推理時僅激活部分參數,成本更低——Maverick 推理成本僅$0.19/百萬token,比GPT-4o便宜90%。
iRoPE實現超長上下文:
iRoPE(交錯旋轉位置編碼)是Meta為Llama 4設計的升級版位置編碼技術。
局部注意力層:用旋轉位置編碼(RoPE)處理短上下文(如8K token),保留位置關系。
全局注意力層:直接去掉位置編碼(NoPE),通過動態調整注意力權重處理超長內容,類似“模糊匹配”長距離關聯。
就像讀書時用書簽(RoPE)標記重點段落,同時靠記憶(NoPE)串聯全書脈絡。

埋葬RAG技術?
相比RAG技術,iRoPE無需依賴外部知識庫檢索,直接通過模型內部自身處理完整信息,減少信息丟失風險,預計未來會成為大模型技術標配,以后大模型容易忘記前文的事情,基本就不會出現了。
開源但有限制:商用需遵守 Meta 政策,月活超7億的公司需額外授權,且產品名必須帶“Llama”。
鯨哥在Together AI上體驗了Llama 4 Scout,并沒有什么特別的強悍之處,DeepSeek對比之下體感還是強很多。Llama 4有點像Google,“參數沒輸過,實戰沒贏過”。
一句話總結:Meta 這次把開源AI卷到新高度,多模態+長上下文+超低成本,Llama 4 可能是目前最香的開源大模型之一。
但下周OpenAI o3和Claude等新模型發布,Llama 4估計又會被奪走注意力。
而且最新消息,Meta高層在后訓練階段中,將多個benchmark測試集混入訓練數據。有副總裁因為Llama刷分問題憤而辭職,也就說目前官宣的成績有很大的水分。
Meta旗下擁有Facebook、Whatsapp等知名社交APP,全球還有超30億月活用戶,這波Meta在AI領域為了掩飾落后卻公然造假,留給市場一句嘆息。
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2025 上海东方报业有限公司

