- +1
AI領域的全面戰爭,從AI爬蟲毀滅互聯網開始
原創 數字生命卡茲克 數字生命卡茲克
昨天看到一個非常有意思的事情。

這是第一次,全世界最大的網絡基礎設施公司之一,Cloudflare,開始用魔法打敗魔法,用AI來對抗AI爬蟲。
這事情的有意思的程度,足以載入AI發展史冊。
這是一次,AI領域的全面戰爭。
你可能現在還有很多疑惑,Cloudflare是什么,AI爬蟲是什么,AI迷宮又是什么,這個事到底有意思在哪。
這一切的開始,我想先跟你講一個故事。
一個在今年1月份,發生在一個僅有7人的烏克蘭公司的故事。
這個公司叫做Triplegangers,做的業務特別簡單,就是賣人的3D數字模型。
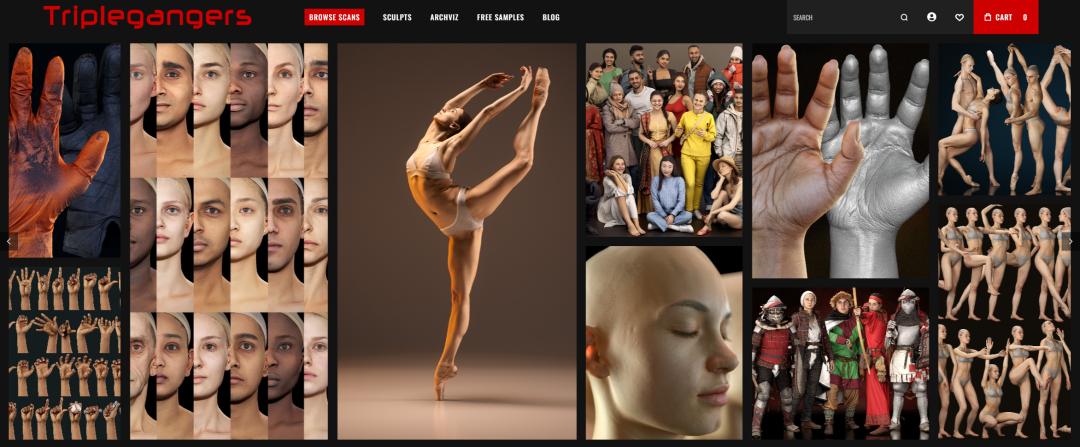
Triplegangers專注于銷售“人體的數字孿生”模型素材,這些高清3D模型照片來自真實的人類掃描,價值巨大。
創始人Tomchuk一直很滿意,公司雖然不大,但是是他最喜歡的事情。
這個網站上,一共共有65000個產品頁面,每個產品的頁面至少放著三張高清照片。 每一張圖片,都細致地標注了年齡、膚色、紋身甚至傷疤。
但是,就在一個普通的周六早上, 平靜被一場風暴驟然打破。
Tomchuk收到了一條緊急通知:公司網站崩潰了,因為受到了大量的DDoS攻擊。
他懵逼了,因為平時也沒啥仇人,更沒啥競品,守著自己那一畝三分地,誰會好好的來攻擊自己呢?
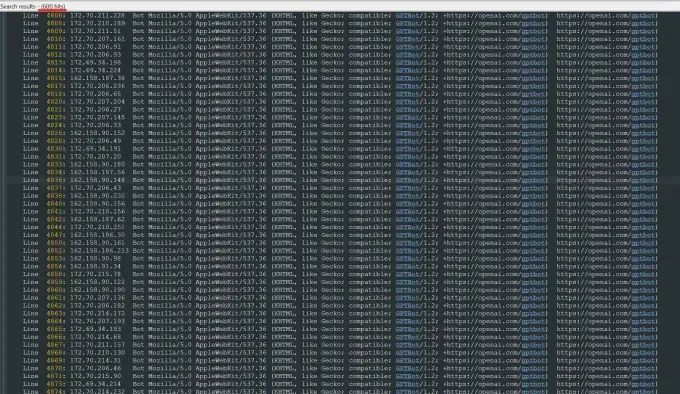
他驚慌失措地開始調查原因,很快發現,居然是OpenAI的爬蟲機器人,GPTBot在攻擊他的網站。
GPTBot瘋狂地爬取每一個頁面, 數十萬張照片、數十萬個描述, 在短短幾小時內被無情下載。
這些爬蟲機器人使用了整整600個IP地址,數以萬計的服務器請求,這種網站哪見過這種架勢,網站的服務器瞬間癱瘓,業務陷入停滯。
Tomchuk人都傻了,不僅自己的數據全丟了,被OpenAI爬的干干凈凈,更糟的是,由于服務器壓力暴漲, 公司還將面臨一筆巨額的AWS賬單。
他們這個七人的團隊花了十年心血,才構建了這個龐大的數據庫,客戶遍及游戲開發、動畫制作等多個行業。
而現在,啥也沒了。
更令人無奈的是,他們原本就明確禁止爬蟲機器人未經許可抓取網站數據。
但是因為沒那么懂AI,也不太知道那些AI大模型公司的玩法,所以沒有嚴格配置robot.txt 文件,沒有配專門告知OpenAI的機器人GPTBot不要訪問該網站的標簽,這基本等同于默認允許了OpenAI的抓取行為。
關鍵是吧,配了GPTBot的標簽也不夠,因為OpenAI還有ChatGPT-User和OAI-SearchBot,這兩個標簽也要配。你甚至不知道他們還有啥。
"我們原以為禁止條款就足夠了,沒想到還必須專門設定拒絕機器人的規則。"
幾天后,Tomchuk終于設置好了Triplegangers的robot.txt文件,并啟用了Cloudflare服務以屏蔽更多爬蟲。
Cloudflare大家可能沒聽過,但是大多數人應該都見過。
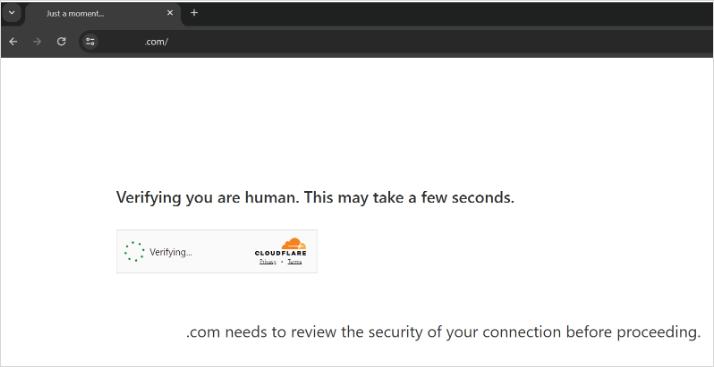
就這個玩意,讓你在進入某些網頁之前,驗證一下你是否是人類。
不過這玩意也不是免費的,挺燒錢的,都是成本。但是為了再防一波OpenAI那種流氓行為,他們只能啟用。
這些服務的錢,都還好說,但是讓Tomchuk最痛苦的事,他根本不知道,OpenAI到底拿走了多少素材。
而且,Tomchuk說:
"我們甚至聯系不上OpenAI,也無法要求他們刪除已抓取的數據。"
甚至最離譜的是,如果不是OpenAI這么貪,一次性請求太多,直接把Triplegangers爬崩潰了,而是慢慢爬,一點一點的。
Tomchuk可能這輩子都發現不了自己的數據已經全部丟的干干凈凈了。
OpenAI的爬蟲邏輯很簡單,如果你家門口沒有保安站崗,那就說明你默認你家里的東西我就都可以拿走,都是我的。因為你沒說不準我拿,也沒設保安,所以我就可以進門全部洗劫一空。
這是一場戰爭。
一場沒有硝煙的戰爭。
一場關乎于保護自己財產神圣不可侵犯的戰爭。
一場關乎于我們,跟這些AI公司的AI爬蟲的戰爭。
Trilegangers的遭遇并不是孤例。
在許多許多公司和內容創作者的眼中,AI爬蟲就是這個時代的數字蝗蟲,所過之處令網站不堪重負,數據還被洗劫一空。
去年夏天,還有一個著名的的例子,來自于非常老牌的維修教程網站,iFixit。
iFixit發現,他們的網站也成了AI爬蟲的盤中餐。
但這一次,吃相難看的不是OpenAI,而是另一個AI王者,Anthropic公司的爬蟲ClaudeBot。
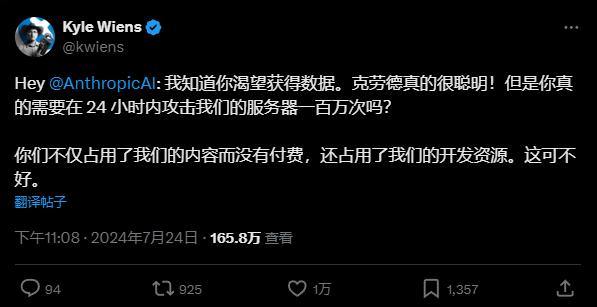
當時iFixit的CEO怒不可遏地在社交媒體上爆料:
ClaudeBot在短短24小時內瘋狂訪問了iFixit近一百萬次。直接差點把他們的網站擠爆,觸發了所有報警系統,迫使iFixit的運維團隊連夜加班處理。
更離譜的是,iFixit早就明文禁止未經許可抓取他們的內容用于AI訓練,這一條清清楚楚地寫進了網站的使用條款,甚至特別注明“不得將本網站內容用于機器學習或AI模型的訓練”。
但是Anthropic的爬蟲明顯不care這些聲明,依舊我行我素地狂扒數據。
更讓無語的是,當這事爆了之后,有媒體就去問Anthropic,對方給出的回應幾乎和OpenAI如出一轍:
他們表示ClaudeBot爬蟲是遵守robots.txt的,如果網站不想被抓,就應該在 robots 文件里屏蔽Claude。
言下之意,就是iFixit你自己明明沒說啊,沒在robots.txt徹底封禁啊,我們當然就有權一直爬下去啊。
無奈之下,iFixit只好趕緊修改了robots.txt,添加了針對ClaudeBot的延遲和阻止規則。
可這件事留給業界的震動卻揮之不去,坦率的講,連iFixit這樣熟悉網絡技術的知名網站,一開始都沒料到 AI 爬蟲會如此不講武德,明知道別人不情愿卻還要硬闖。
如果連老牌互聯網從業者都防不勝防,那其他那些沒技術團隊守衛的小網站、小作者,又咋招架這些竊賊?
甚至更不要臉的是那個AI搜索鼻祖,Perplexity。
知名科技媒體《連線》(Wired)發現,Perplexity的爬蟲不僅沒有遵守一些網站的robots.txt 禁令,甚至試圖悄悄抓取那些明確聲明不開放給機器的角落。
換句話說,就是Perplexity公然無視robots協議,偷偷攫取了本不該拿的內容。
可能你看到這里,會疑惑robots協議是個啥。
我們把時間倒回1994年,那個時候網絡上也正經歷著爬蟲之亂。
彼時搜索引擎剛興起,一些自動爬蟲程序在網上橫沖直撞,給服務器造成了不小的負擔。
于是,一位名叫Martijn Koster的荷蘭工程師,提出了一個非常巧妙的主意:
網站管理員可以在站點根目錄放一個名為“robots.txt”的文本文件,提前告訴網絡機器人,哪里可以爬、哪里不許碰。
這個提議很快得到了行業的廣泛認可,成為互聯網早期一種非常純粹的“君子協定”。
根據robots協議,如果網站在robots.txt里標明了禁止抓取某些內容,那么守規矩的爬蟲就應該乖乖止步,不去觸碰那些被列入黑名單的路徑。
這套機制本質上完全依賴自覺,它沒有法律強制力,靠的是爬蟲開發者愿意遵守規則的良知和誠意。
但令人欣慰的是,在相當長的歲月里,這種誠意基本上保持了下來。
Google、Yahoo等搜索引擎尊重robots.tx 的邊界,微軟的Bing也是如此,甚至后來各式各樣善意的網絡爬蟲,都把不傷害網站、遵循站長意愿當作職業道德的一部分。
正因為有robots.txt的存在,網站管理員才愿意敞開大門讓搜索引擎索引內容,他們相信敏感或不想公開的角落可以被禮貌地避開。
這份信任,構筑了網絡內容自由流通和公平利用的基礎。
但是現在,這份來之不易的信任正被無情地侵蝕。
當AI爬蟲為了填飽模型的數據需求四處出擊時,又有多少還真正尊重 robots.txt的邊界?
OpenAI、Anthropic固然口口聲聲我們遵守robots協議,但事實是,如果你沒明確寫禁令,他們就默認可以來拿,絲毫不考慮你是否情愿。
只要你沒用足夠堅固的墻把我擋住,那就是你的錯,我闖進來就理所應當。
這種倒打一耙的邏輯讓人憤慨之余,也透出一絲悲哀。
所以,在這種背景下,Cloudflare挺身而出,作為大多數網站前的守護者,他們決定,用魔法打敗魔法,用AI,對抗AI。
他們為這些AI爬蟲,造了一整座AI迷宮。
因為過往的防御邏輯很簡單,就是用驗證的方式,直接把這些AI爬蟲攔在門外,這樣會有個問題,反而會驚動敵人,讓他們換個馬甲卷土重來。
比如OpenAI就有N個AI爬蟲。
所以他們這次的更新,用了一個更陰柔的做法:
放對手進來,但是領著它走進一個精心編織的虛假網頁迷宮。
在這個迷宮里,所有的頁面、鏈接和內容都是 AI 自動生成的,看上去像模像樣,卻全都是無意義的空城計。
那些AI爬蟲一旦被引誘進去,就會在假內容中團團轉,白白浪費計算資源和帶寬。
而這些迷宮入口對正常用戶是隱形的,真人訪客根本不會點擊到那些陷阱鏈接。而 AI 爬蟲則樂此不疲地一路追蹤下去,越陷越深,直到在虛假的信息泥潭中迷失方向。
大衛終于也有了一塊對付歌利亞的利器。
Cloudflare他們在blog中寫道:

這是一場戰爭,一邊是如狼似虎、到處搜刮數據的AI爬蟲大軍,另一邊則是苦苦守衛自己數字領土的網站站長和內容創作者們。
我不否認大模型需要海量數據訓練,創新常常伴隨著對舊有規則的沖撞。
互聯網歷史上類似的矛盾并非首次:音樂產業曾與數字盜版激烈交鋒,新聞出版商也為搜索引擎收錄內容而抗議。
也許在很多AI公司看來,網絡上的公開內容皆是取之無害、用之無罪的公共資源,抓了又何妨?
但是有沒有想過內容生產者的感受呢?知識和創意的源頭若得不到尊重和回報,最終枯竭的將是創新本身。沒有人愿意辛苦耕耘卻被機器毫無顧忌地偷走成果。
至少在現有的倫理和經濟體系下,這種行為會磨滅創作者的熱情。
到最后,網絡上留下的,全部是AI生產的AI垃圾,淹沒了整個互聯網。
戰爭已經打響,而AI領域的這場較量正是從爬蟲開始的。
我只希望,當硝煙散去,我們還能擁有一個我們所熱愛的、開放而可信的互聯網。
拋開那些宏大的技術敘事,對于我們每一個普通網民而言。
這才是我們最值得去捍衛的東西。
不是嗎。
>/ 作者:卡茲克
>/ 投稿或爆料,請聯系郵箱:wzglyay@gmail.com
原標題:《AI領域的全面戰爭,從AI爬蟲毀滅互聯網開始。》
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

