- +1
大模型的“三重門”,AI的盡頭是什么?
“我們通向AGI的巔峰之旅,恐非一點之極,而似層巒疊嶂、地形錯綜的高原。”
1956年夏天,新罕布什爾州達特茅斯學院迎來了一場特殊的學術聚會。當數學教授約翰麥卡錫在會議提案中首次寫下Artificial Intelligence這個術語時,或許未曾料到,這場原本計劃用兩個月時間徹底解決機器模擬智能問題的討論,竟開啟了一場跨越世紀的認知革命。
阿里巴巴集團CEO吳泳銘在財報會議上語氣鏗鏘,仿佛預見到歷史轉折的關鍵瞬間:一旦AGI真正實現,其所催生的產業規模,極有可能問鼎全球之首,甚至有可能深刻地影響、乃至部分取代當下全球經濟構成中近半壁江山的產業形態。
在驚喜與擔憂之間,人們正學著接納和擁抱人工智能,惴惴不安地揣測著通用人工智能(AGI)何時到來。然而,作為掀起本輪AI熱潮的主角,大語言模型或許還只是一個探路者,離真正的AGI仍相距甚遠,甚至根本不是通達AGI的正途。對此,人們不免心生疑問,我們離實現真正的AGI還有多遠?

誰是AGI的起點?
通用人工智能(Artificial General Intelligence)一詞最初出現在北卡羅萊納大學物理學家Mark Gubrud于1997年發表的一篇有關軍事技術的文章中,其中將AGI定義為在復雜性和速度上與人腦相媲美或超越的AI系統,可以獲取一般性知識,并以其為基礎進行操作和推理,可以在任何工業或軍事活動中發揮人類智力的作用。
一直以來,AGI被視為人工智能領域的圣杯,它意味著機器能夠像人類一樣,在多種任務中自主學習、推理并適應復雜環境。從GPT-4的對話能力到Sora的視頻生成,盡管近年來AI技術突飛猛進,但AGI的實現仍面臨多重鴻溝。
AI的核心就是把現實世界的現象翻譯成為數學模型,通過語言讓機器充分理解現實世界和數據的關系。而AGI更進一步,讓AI不再局限于單一任務,而是具備跨領域學習和遷移能力,因此具有更強的通用性。
如果比較AGI的特征,就會發現當前AI系統雖然在特定任務上超越人類(如文本生成、圖像識別),但本質上仍是高級模仿,缺乏對物理世界的感知和自主決策能力,依然不符合AGI的要求。
首先,大模型在處理任務方面的能力有限,它們只能處理文本領域的任務,無法與物理和社會環境進行互動。這意味著像ChatGPT、DeepSeek這樣的模型不能真正理解語言的含義,因為它們沒有身體來體驗物理空間。
其次,大模型也不是自主的,它們需要人類來具體定義好每一個任務,就像一只鸚鵡,只能模仿被訓練過的話語。真正自主的智能應該類似于烏鴉智能,能夠自主完成比現如今AI更加智能的任務,當下的AI系統還不具備這種潛能。
第三,雖然ChatGPT已經在不同的文本數據語料庫上進行了大規模訓練,包括隱含人類價值觀的文本,但它并不具備理解人類價值或與人類價值保持一致的能力,即缺乏所謂的道德指南針。
但這些并不妨礙科技巨頭對于大模型的推崇。OpenAI、谷歌在內的科技巨頭,都將大模型視為邁向AGI的關鍵一步。OpenAI CEO薩姆奧特曼(Sam Altman)就曾多次表示,GPT模型是朝著AGI方向發展的重要突破。
根據OpenAI提出的AGI五級標準:L1是聊天機器人(Chatbots),具備基本的會話語言能力;L2是推理者(Reasoners),能夠解決人類級別的問題,處理更復雜的邏輯推理、問題解決和決策制定任務;L3是智能主體(Agents),能夠代表用戶采取行動,具備更高的自主性和決策能力;L4是創新者(Innovators),能夠助力發明和創新,推動科技進步和社會發展;L5是組織者(Organizations),能夠執行復雜的組織任務,具備全面管理和協調多個系統和資源的能力。

當前,AI技術正從L2推理者向L3智能體階段躍遷,而2025年成為Agent(智能體)應用爆發之年是業內共識,我們已經看到像ChatGPT、DeepSeek、Sora這類應用開始進入普及階段,融入人們的工作生活。
但通往AGI的道路仍布滿認知陷阱,大模型偶爾出現的幻覺輸出,暴露出當前系統對因果關系的理解局限;自動駕駛汽車面對極端場景的決策困境,折射出現實世界的復雜性與倫理悖論。
就像人類智能進化塑造的是多層架構,既有本能層面的快速反應,也有皮層控制的深度思考。要讓機器真正理解蘋果落地背后的萬有引力,不僅需要數據關聯,更需要建立物理世界的心智模型。這種根本性的認知鴻溝,可能比我們想象中更難跨越。
通向AGI的必經之路
大模型的演進將會經歷三個階段:單模態多模態世界模型。
早期階段是語言、視覺、聲音各個模態獨立發展,當前階段是多模融合階段,比如GPT-4V可以理解輸入的文字與圖像,Sora可以根據輸入的文字、圖像與視頻生成視頻。
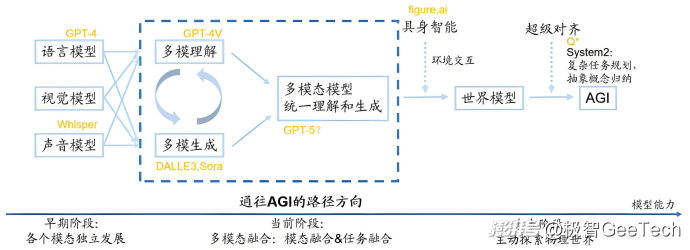
但現階段的多模態融合還不徹底,理解與生成兩個任務是分開進行的,造成的結果是GPT-4V理解能力強但生成能力弱,Sora生成能力強但理解能力有時候很差。多模態理解與生成的統一是走向AGI的必經之路,這是一個非常關鍵的認知。
無論通過哪種路徑實現AGI,多模態模型都是不可或缺的一部分。人與現實世界的交互涉及多種模態信息,因此,AI必須處理和理解多種形式的數據,這意味著其必須具備多模態理解能力。
多模態模型能夠處理和理解不同模態數據的機器學習模型,如圖像、文本、音頻和視頻,能夠提供比單一模態更全面、更豐富的信息表達。此外,模擬動態環境變化并做出預測和決策,也需要強大的多模態生成能力。
不同模態的數據往往包含互補的信息,多模態學習能夠有效地融合這些互補信息,提高模型的準確性和魯棒性。例如,在圖像標注任務中,文本信息可以幫助模型更好地理解圖像內容;而在語音識別中,視頻信息有助于模型捕捉說話者的唇動,從而提高識別準確率。
通過學習和融合多種模態的數據,模型能夠建立更加泛化的特征表示,從而在面對未見過的、復雜的數據時表現出更好的適應性和泛化能力。這對于開發通用智能系統和提高模型在現實世界應用中的可靠性具有重要意義。
多模態模型的研究大致可以分為幾種技術途徑:對齊、融合、自監督和噪聲添加。基于對齊的方法將不同模態的數據映射到一個共同的特征空間進行統一處理。融合方法將多模態數據整合到不同的模型層中,充分利用每個模態的信息。自監督技術在未標記的數據上對模型進行預訓練,從而提高各種任務的性能。噪聲添加通過在數據中引入噪聲來增強模型的魯棒性和泛化能力。
結合這些技術,多模態模型在處理復雜的現實世界數據方面表現出強大的能力。它們可以理解和生成多模態數據,模擬和預測環境變化,并幫助智體做出更精確和有效的決策。因此,多模態模型在發展世界模型中起著至關重要的作用,標志著邁向AGI的關鍵一步。
比如微軟近日開源了多模態模型Magma,不僅具備跨數字、物理世界的多模態能力,能自動處理圖像、視頻、文本等不同類型數據,還能夠推測視頻中人物或物體的意圖和未來行為。
階躍星辰兩款Step系列多模態大模型Step-Video-T2V、Step-Audio已與吉利汽車星睿AI大模型完成了深度融合,推動AI技術在智能座艙、高階智駕等領域的普及應用。
蘑菇車聯深度整合物理世界實時數據的AI大模型MogoMind,具備多模態理解、時空推理與自適應進化三項能力,不僅能夠處理文本、圖像等數字世界數據,還能通過城市基礎設施(如攝像頭、傳感器)、車路云系統以及智能體(如自動駕駛車輛)實現對物理世界的實時感知、認知和決策反饋,突破了傳統模型依賴互聯網靜態數據訓練、無法反映物理世界實時狀態的局限。同時,該大模型還重構視頻分析范式,使普通攝像頭具備行為預測、事件溯源等高級認知能力,為城市和交通管理者提供流量分析、事故預警、信號優化等服務。
不過,多模態在發展過程中,還需要面臨數據獲取和處理的挑戰、模型設計和訓練的復雜性,以及模態不一致和不平衡的問題。
多模態學習需要收集和處理來自不同源的數據,不同模態的數據可能有著不同的分辨率、格式和質量,需要復雜的預處理步驟來確保數據的一致性和可用性。此外,獲取高質量、標注精確的多模態數據往往成本高昂。
其次,設計能夠有效處理和融合多種模態數據的深度學習模型比單模態模型更加復雜。需要考慮如何設計合適的融合機制、如何平衡不同模態的信息貢獻、以及如何避免模態間的信息沖突等問題。同時,多模態模型的訓練過程也更為復雜和計算密集,需要更多的計算資源和調優工作。
在多模態學習中,不同模態之間還可能存在顯著的不一致性和不平衡性,如某些模態的數據可能更豐富或更可靠,而其他模態的數據則可能稀疏或含噪聲。處理這種不一致和不平衡,確保模型能夠公平、有效地利用各模態的信息,也是多模態學習中的一個重要挑戰。
當前,大語言模型、多模態大模型對人類思維過程的模擬還存在天然的局限性。從訓練之初就打通多模態數據,實現端到端輸入和輸出的原生多模態技術路線給出了多模態發展的新可能。基于此,訓練階段即對齊視覺、音頻、3D等模態的數據實現多模態統一,構建原生多模態大模型,成為多模態大模型進化的重要方向。
將AI拉回現實世界
Meta人工智能首席科學家楊立昆(Yann LeCun)認為,目前的大模型路線無法通往AGI。現有的大模型盡管在自然語言處理、對話交互、文本創作等領域表現出色,但其仍只是一種統計建模技術,通過學習數據中的統計規律來完成相關任務,本質上并非具備真正的理解和推理能力。
他認為,世界模型更接近真正的智能,而非只學習數據的統計特征。以人類的學習過程為例,孩童在成長過程中,更多是通過觀察、交互和實踐來認知這個世界,而非被單純注入知識。
例如,第一次開車的人在過彎道的時候會自然地知道提前減速;兒童只需要學會一小部分(母語)語言,就掌握了幾乎這門語言的全部;動物不會物理學,但會下意識地躲避高處滾落的石塊。
世界模型之所以引起廣泛關注,原因在于其直接面對了一個根本性的難題:如何讓AI真正理解和認識世界。它正試圖通過對視頻、音頻等媒體的模擬與補全,讓AI也經歷這樣一個自主學習的過程,從而形成常識,并最終實現AGI。
世界模型和多模態大模型主要有兩方面不同之處,一是世界模型主要通過包括攝像頭在內的傳感器直接感知外部環境信息,相比于多模態大模型,其輸入的數據形式以實時感知的外部環境為主,而多模態大模型則是以圖片、文字、視頻、音頻等信息交互為主。
另一方面,世界模型輸出的結果,更多的是時間序列數據(TSD),并通過這個數據可以直接控制機器人。同時物理智能需要與現實世界進行實時、高頻交互,其對時效性要求較高,而多模態大模型更多是與人交互,輸出的是過往一段時間的靜態沉淀信息,對時效性要求較低。
也正因此,世界模型也被行業人士看作是實現AGI的一道曙光。

世界模型的發展雖然取得了顯著進展,但仍面臨多方面的挑戰。挑戰之一是在模擬環境動態及因果關系方面的能力,以及進行反事實推理的能力。反事實推理要求模型能夠模擬如果環境中的某些因素發生變化,結果會如何不同,這對于決策支持和復雜系統模擬至關重要。
例如,在自動駕駛中,模型需要能夠預測如果某個交通參與者的行為發生變化,車輛的行駛路徑會受到怎樣的影響。然而,當前的世界模型在這一領域的能力有限,未來需要探索如何讓世界模型不僅反映現實狀態,還能根據假設的變化做出合理的推斷。
物理規則的模擬能力是世界模型面臨的另一大挑戰,尤其是如何讓模型更加精確地模擬現實世界中的物理規律。盡管現有的視頻生成模型如Sora可以模擬一定程度的物理現象(如物體運動、光反射等),但在一些復雜的物理現象(如流體動力學、空氣動力學等)中,模型的準確性和一致性仍然不足。
為了克服這一挑戰,研究人員需要在模擬物理規律時,考慮更精確的物理引擎與計算模型,確保生成的場景能夠更好地遵循真實世界中的物理定律。
評估世界模型性能的關鍵標準之一是泛化能力,其強調的不僅是數據內插,更重要的是數據外推。例如,真實的交通事故或異常的駕駛行為是罕見事件。那么,學習得到的世界模型能否想象這些罕見的駕駛事件,這要求模型不僅要超越簡單地記憶訓練數據,而且要發展出對駕駛原理的深刻理解。通過從已知數據進行外推,并模擬各種潛在情況,使其可以更好地應用于現實世界之中。
對于AI而言,讓機器人親自擰開瓶蓋獲取的數據,比觀看百萬次操作視頻更能建立物理直覺。通過在模型訓練過程中加入更多真實場景的實時動態數據,可以讓AI更好理解三維世界的空間關系、運動行為、物理規律,從而實現對物理世界的洞察和理解。最終,AGI的到來可能不像奇點理論預言的那般石破天驚,而會像晨霧中的群山,在數據洪流的沖刷下漸次顯形。
AI的盡頭并非一個固定終點,而是人類與技術共同書寫的未來敘事。它可能是工具、伙伴、威脅,或是超越想象的形態。關鍵問題或許不是AI的盡頭是什么,而是人類希望以何種價值觀引導AI的發展。正如斯蒂芬霍金所警示:AI的崛起可能是人類最好或最糟的事件。答案取決于我們今天的決策與責任,屆時AI將重新認識世界,并完成對未來人機交互方式的重新想象。
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

