- +1
Google Cloud發布下一代TPU和GPU集群,增強AI Hypercomputer堆棧
Google Cloud正在更新面向AI工作負載的AI Hypercomputer堆棧,并宣布推出了一系列新處理器和基礎設施軟件產品。
Google宣布推出了第六代張量處理單元Trillium TPU,以及即將推出由Nvidia H200 GPU驅動的新型A3 Ultra虛擬機,此外還有基于Axion Arm架構的C4A VM,從今天正式面世。
谷歌還推出了新的軟件,包括一個名為Hypercompute Cluster的高度可擴展集群系統,以及Hyperdisk ML塊存儲和并行文件系統。
Google Cloud副總裁、計算和AI基礎設施總經理Mark Lohmeyer在一篇博文中表示,AI Hypercomputer堆棧為企業提供了一種方法,可以把工作負載優化的硬件(例如谷歌的TPU和GPU)與一系列開源軟件集成在一起,以支持廣泛的AI工作負載。
他表示:“這種整體方法優化了堆棧的每一層,在最廣泛的模型和應用中實現了無與倫比的規模、性能和效率。”
Lohmeyer表示,谷歌希望提高AI Hypercomputer堆棧的性能,同時使其更易于使用,且運行成本更低。要做到這一點,就需要一套先進的新功能,這正是谷歌今天推出的。
這次最重要的發布是Trillium TPU,它為客戶提供了Nvidia主流GPU的一個強大替代品,并且已經被谷歌用于支持高級AI應用,例如Gemini系列大型語言模型。Trillium TPU現已面向所有客戶推出預覽版,與谷歌第五代TPU相比,Trillium TPU有了顯著改進。
例如,它在AI訓練方面的性能提升了4倍,推理吞吐量方面提升了3倍,能源效率方面提升了67%,峰值計算性能提高了4.7倍,同時高帶寬內存容量增加了1倍,芯片間互連帶寬也增加了1倍。
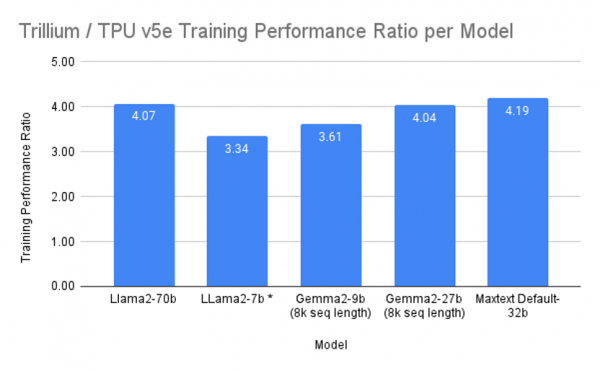
內存和帶寬的增加,意味著Trillium可以運行更大的大型語言模型,具有更多的權重和更大的鍵值緩存。此外,它還允許芯片在訓練和推理方面支持更廣泛的模型架構,成為訓練Gemma 2和Llama等大型語言模型以及“Mixture-of-Experts”(MoE)機器學習技術的理想選擇。
Lohmeyer表示,Trillium可以擴展到一個配置了256個芯片的集群容納在一個高帶寬、低延遲的pod中,可以使用最先進的芯片間互連技術將其鏈接到其他pod,這就意味著客戶擁有無限的可能性,他們可以靈活地連接數百個pod和數萬個Trillium TPU,以打造“建筑規模”的超級計算機,并由每秒13千兆比特的Jupiter數據中心網絡提供支持。
“我們設計TPU是為了優化性價比,Trillium也不例外,與v5e TPU相比,它的性能提高了1.8倍,與v5p相比,性能提高了約2倍,這使Trillium成為我們迄今為止性價比最高的TPU。”
采用Nvidia H100 GPU的A3 Ultra VM
當然,Google Cloud的客戶并不局限于使用Trillium TPU,因為谷歌還是繼續大量購買Nvidia最強大的GPU。谷歌已經使用Nvidia H100 GPU打造了最新的A3 Ultra VM,據說與現有的A3和A3 Mega VM相比,性能上有了顯著的提升。
Lohmeyer表示,A3 Ultra VM將于下個月登陸Google Cloud,利用谷歌新的Titanium ML網絡適配器和數據中心范圍的四向軌道對齊網絡,提供高達每秒3.2兆比特的GPU到GPU傳輸流量。
因此,GPU到GPU帶寬的帶寬將提高2倍,大型語言模型推理工作負載性能提高2倍,內存容量增加近2倍,帶寬增加1.4倍,這些都將讓客戶從中受益。就像TPU一樣,客戶可以選擇將數萬個GPU連接到一個密集的高性能集群中,以處理那些要求最苛刻的AI工作負載,從而擴展部署規模。

A3 Ultra VM可以被作為獨立的計算選項使用,也可通過Google Kubernetes Engine使用,后者為客戶提供了一個開放的、便攜的、可延伸和可擴展的AI訓練和服務平臺。
基于Google Axion CPU的C4A VM
當然谷歌承認,并非每個AI用例都需要如此強大的馬力,因為有很多類型的通用AI工作負載用較低的功率就可以運行起來。在這種情況下,優化堆棧以降低成本是有意義的,而這時候新C4A VM就能派上用場了。
C4A VM是由Google Axion CPU提供支持的,后者是谷歌首款基于Arm架構的數據中心CPU。

谷歌給出了一些有趣的說法,稱C4A VM的性價比比競爭對手云平臺上最新基于Arm的實例要高出10%,而且和當前一代基于x86的實例相比也非常出色,性價比高出65%,對于通用工作負載(例如Web和應用服務器、數據庫工作負載和容器化微服務)而言,能效高出60%。
Constellation Research分析師Holger Mueller表示,這款新硬件進一步鞏固了Google Cloud作為AI開發者最佳云基礎設施平臺的地位。谷歌借助Trillium TPU在把TensorFlow等客戶算法應用到客戶硬件方面,領先競爭對手三到四年。
Mueller表示:“除了性能改進之外,Trillium在能效方面提升67%,這看起來也非常重要,因為功耗因素對每個組織都變得越來越重要,看到網絡速度和帶寬的提高也令人欣喜,這可以滿足更大模型的需求。”
此外Mueller表示,Google Cloud的客戶會很高興知道谷歌正準備支持Nvidia最強大的GPU,包括定于明年推出的Blackwell GPU。
“現在是成為Google Cloud客戶的一個好時機,而且有很多這樣的客戶,因為越來越多的企業已經意識到這是一個值得使用的平臺,一旦這些更新的影響開始顯現,我們可以期待看到Google Cloud在AI領域的領導地位得到進一步確認。”
支持堆棧
除了新硬件之外,谷歌還對組成AI Hypercomputer的底層存儲和網絡組件、以及將一切連接一起的軟件進行了重大改進。
谷歌通過最新的Hypercompute Cluster來簡化基礎設施和工作負載配置,這樣客戶就可以把數千個加速器作為一個單元部署和管理。這款軟件將在下個月推出,提供諸如支持密集的資源共置、有針對性的工作負載放置、高級維護以最大限度地減少工作負載中斷和超低延遲網絡等。
“Hypercompute Cluster旨在提供卓越的性能和彈性,因此您可以放心地運行那些最苛刻的AI和HPC工作負載,”Lohmeyer說。
與此同時,谷歌的Cloud Interconnect網絡服務正在更新一項圍繞“應用感知”的新功能,旨在解決流量優先級方面的難題。具體來說,它可以確保在網絡流量擁堵時,從Google Cloud流出的低優先級流量不會對高優先級流量產生不利的影響。谷歌表示,另一個好處是可以降低總擁有成本,因為它可以更有效地利用Cloud Interconnect上的可用帶寬。
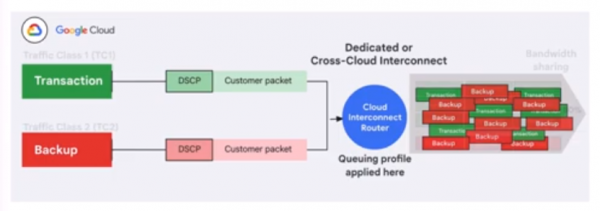
其他方面,谷歌還對Titanium基礎設施進行了增強,后者是一個卸載技術系統,可用于減少處理開銷并增加每個工作負載可用的計算和內存資源量。增強之后的Titanium可以支持最苛刻的AI工作負載,利用新的Titanium ML網絡適配器來增加加速器到加速器的帶寬,而且還采用了谷歌的Jupiter光纖電路交換網絡結構,該結構可以提供高達每秒400千兆位的鏈接速度。
最后,谷歌宣布Hyperdisk ML塊存儲服務已經全面上市,該服務于今年4月開始提供預覽版。這是一款專注于AI的存儲解決方案,針對系統級性能和成本效益進行了優化,模型加載時間提高了11.9倍,AI訓練時間加快了4.3倍。
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

