- +1
GPT-4o mini實測:小模型也好用,低價更是殺手锏

北京時間 7 月 18 日晚,OpenAI 難得推出了一個「小模型」——GPT-4o mini。
顧名思義,GPT-4o mini 是 OpenAI 在 GPT-4o 基礎上進行的一次嘗試。官方表示,GPT-4o mini 在文本智能和多模態推理方面的基準性能超越了 GPT-3.5 Turbo,甚至在 LMSYS「聊天機器人對戰」排行榜上還強過 GPT-4。
此外,GPT-4o mini 還支持 128K Token 的長上下文窗口,以及每個請求最多 16K Token 的輸出。簡而言之,GPT-4o mini 可以記憶比 GPT-3.5 Turbo 長得多的內容和對話,還能在單次輸出更長的回答。
不過 GPT-4o mini 的核心,還是提供更好的成本效益。
根據 OpenAI 指出,GPT-4o mini 不僅性能更強,價格也來到了「白菜價」。具體來講,GPT-4o mini 每百萬個輸入 Token 的定價是 15 美分(約合人民幣 1.09 元),每百萬個輸出 Token 的定價是 60 美分(約合人民幣 4.36 元):
比 GPT-3.5 Turbo 便宜超過 60%。
對普通用戶來說,更重要的是 GPT-4o 將在 ChatGPT 中全面替代 GPT-3.5 Turbo,免費用戶也能使用。到今天(7 月 19 日)早上,小雷已經在 ChatGPT 看到了 GPT-4o mini,而不是 GPT-3.5。
圖/雷科技
另據 VentureBeat 采訪,OpenAI 產品負責人兼 API 部門主管 Olivier Godement 表示,GPT-4o mini 將在今年秋天通過蘋果的 Apple Intelligence,為旗下的移動設備和 Mac 設備提供服務。
不過這里還有一個可能存在的誤解,盡管 GPT-4o mini 比 GPT-4o 等大模型要小得多,但其規模依然比手機上搭載的端側大模型(基本不超過 7b)大得多。因此,在 iOS 18 等系統上,GPT-4o mini 還是通過云端而非本地的形式提供服務。
GPT-4o mini,更好用更便宜的 GPT
OpenAI 發布 GPT-4o mini 之后,很多人最先關心的一個問題可能是:GPT-4o mini,相比 GPT-4 和 GPT-4o 用起來的表現如何?
用一個例子來簡單說明下,分別詢問通過這三個模型詢問 ChatGPT:「介紹下 OpenAI 最新發布的 GPT-4o mini 模型。」
在生成結果上,GPT-4o mini 的回答并不包含任何數據,內容相對空洞,但相關描述基本正確。考慮到 OpenAI 指出 GPT-4o mini 只具有截至 2023 年 10 月的知識,且在 ChatGPT 中不支持聯網,可以說明 GPT-4o mini 是從命名作出的「推測」。

GPT-4o mini,圖/雷科技
相比之下,GPT-4(未經聯網搜索)告訴我「OpenAI 并沒有發布名為『GPT-4o mini』的模型」,直到主動要求聯網搜索,才真正開始介紹。不過即便如此,GPT-4 還是沒有明顯超出 GPT-4o mini 生成的答案,就算明確問它「成本有多低」,也沒能給出讓人滿意的答案。

GPT-4,圖/雷科技
至于 GPT-4o(自動聯網搜索),作為目前 OpenAI 旗下甚至全世界最強大的模型,其表現毋庸置疑。更詳略得當的介紹、更確鑿的數據和引用鏈接,都讓它能夠繼續穩坐大模型的頭把交椅。

GPT-4o,圖/雷科技
簡單總結一下,GPT-4o mini 相比之前的 GPT-3.5 有著明顯的進步,甚至相比 GPT-4 也有一定優勢。雖然我目前的幾個簡單測試基本符合 OpenAI 和 LMSYS 排行榜給出的結論,但要下最終結論還是太早。如果大家有需求,后續可以做更全面的對比。
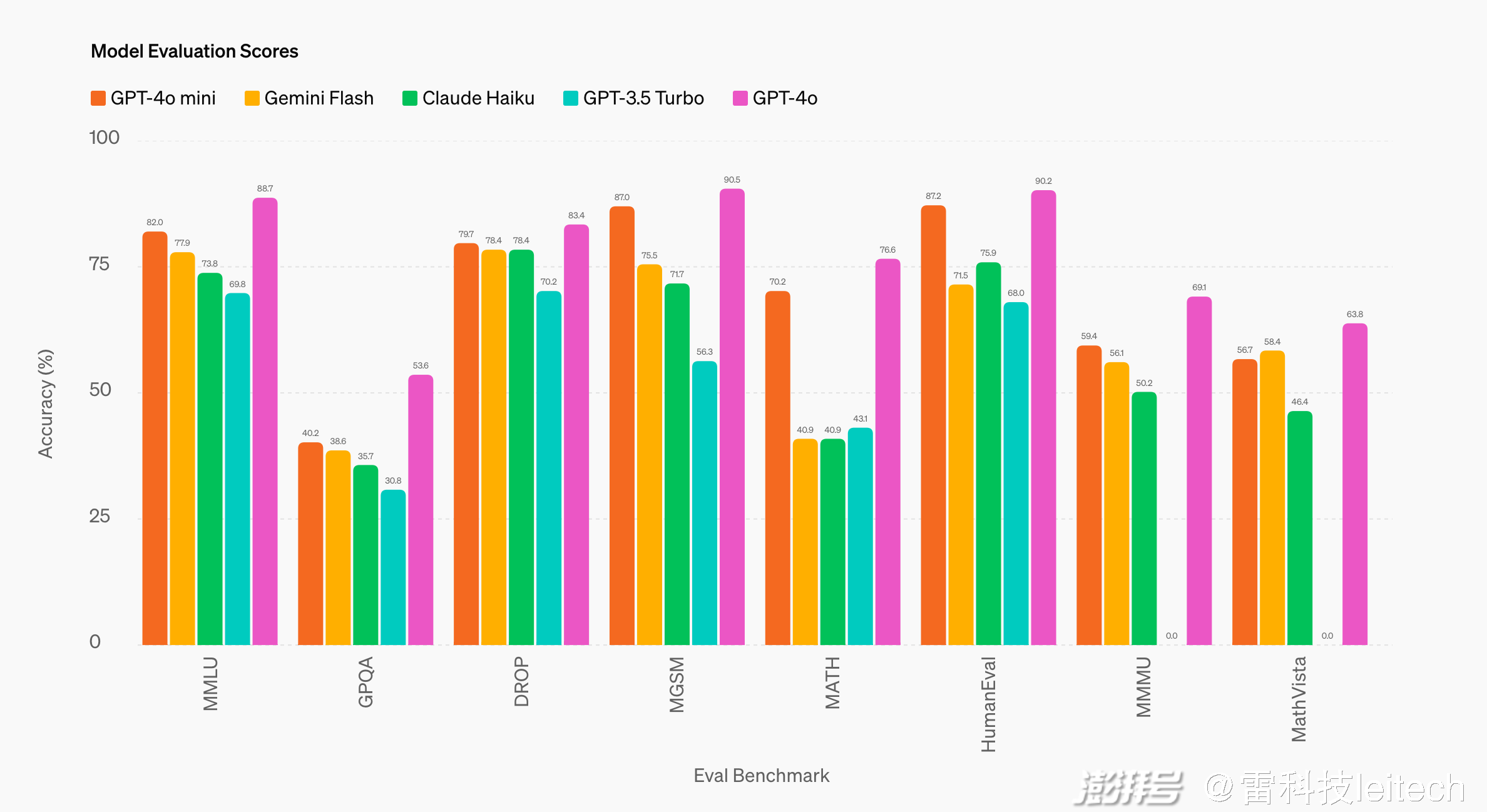
另外,OpenAI 也公布 GPT-4o mini 在不同基準下的「跑分成績」,以供參考:
圖/ OpenAI
總體來看,相比 Gemini 1.5 Flash、Claude 3 Haiku 這兩個同樣主打「性價比」的模型(由超大模型衍生),GPT-4o mini 的優勢還是比較明顯,尤其是在 MGSM(數學推理)、MATH(數學解決)、HumanEval(代碼生成)等方面。
同時 OpenAI 還表示,GPT-4o mini 在 API 中支持文本,之后還會逐步增加圖像、視頻和音頻的輸入輸出支持,且得益于與 GPT-4o 共享的改進 Token 生成器,處理非英語文本現在更加經濟高效。
在 GPT-4o mini 推出之后,馬上就有海外和國內的開發者計劃切換到 GPT-4o mini 試試,比如前愛范兒副總裁兼首席設計官@Ping.開發的 AI 語音筆記 App「閃念貝殼」:
圖/ X@Ping.
事實上,對于 GPT-4o mini 來說,現階段最核心也最重要的用戶是 API 面向的開發者,而非 ChatGPT 面向的普通用戶。
OpenAI 為什么要推出 GPT-4o?
對于 OpenAI 來說,推出 GPT-4o mini 是一件比較反常的事情,因為在此之前,從 GPT-1/2/3、GPT-3.5 到 GPT-4、GPT-4o,OpenAI 都是在推出更強的大模型,沖擊機器智能的天花板。就算是 Turbo 系列,也是同等性能下優化速度和成本。
但在 GPT-4o mini 上,OpenAI 選擇了縮小模型規模、降低模型性能,以實現更具成本效益的生成式 AI 模型。
問題在于,在 OpenAI 之前,很多大模型廠商從一開始就是「大中小模型」并進的策略,就算是谷歌 Gemini 和 Anthropic Claude,也都分別推出 Gemini 1.5 Flash 和 Claude 3 Haiku。
對此,Olivier Godement 的解釋是,OpenAI 專注于創建更大、更好的模型,如 GPT-4,這需要大量的人力和計算資源。不過隨著時間的推移,OpenAI 注意到開發人員越來越渴望使用較小的模型,因此公司決定投入資源開發 GPT-4o mini,并于現在推出。
「我們的使命是使用最前沿技術,構建最強大、最有用的應用程序,我們當然希望繼續做前沿模型,推動技術進步,」Olivier Godement 在采訪中說,「但我們也希望擁有最好的小模型,我認為它會非常受歡迎。」

圖/ OpenAI
簡單來說,就是優先級的問題。但在優先級的背后,是越來越多公司偏好中小型的生成式 AI 模型。
WSJ 近期的一篇報道,就援引多家公司高管以及 Google Cloud 全球生成式 AI 產品上市策略副總裁 Oliver Parker 指出,過去三個月,企業正在集體轉向更小參數規模的生成式 AI 模型。
成本當然是最核心的原因。
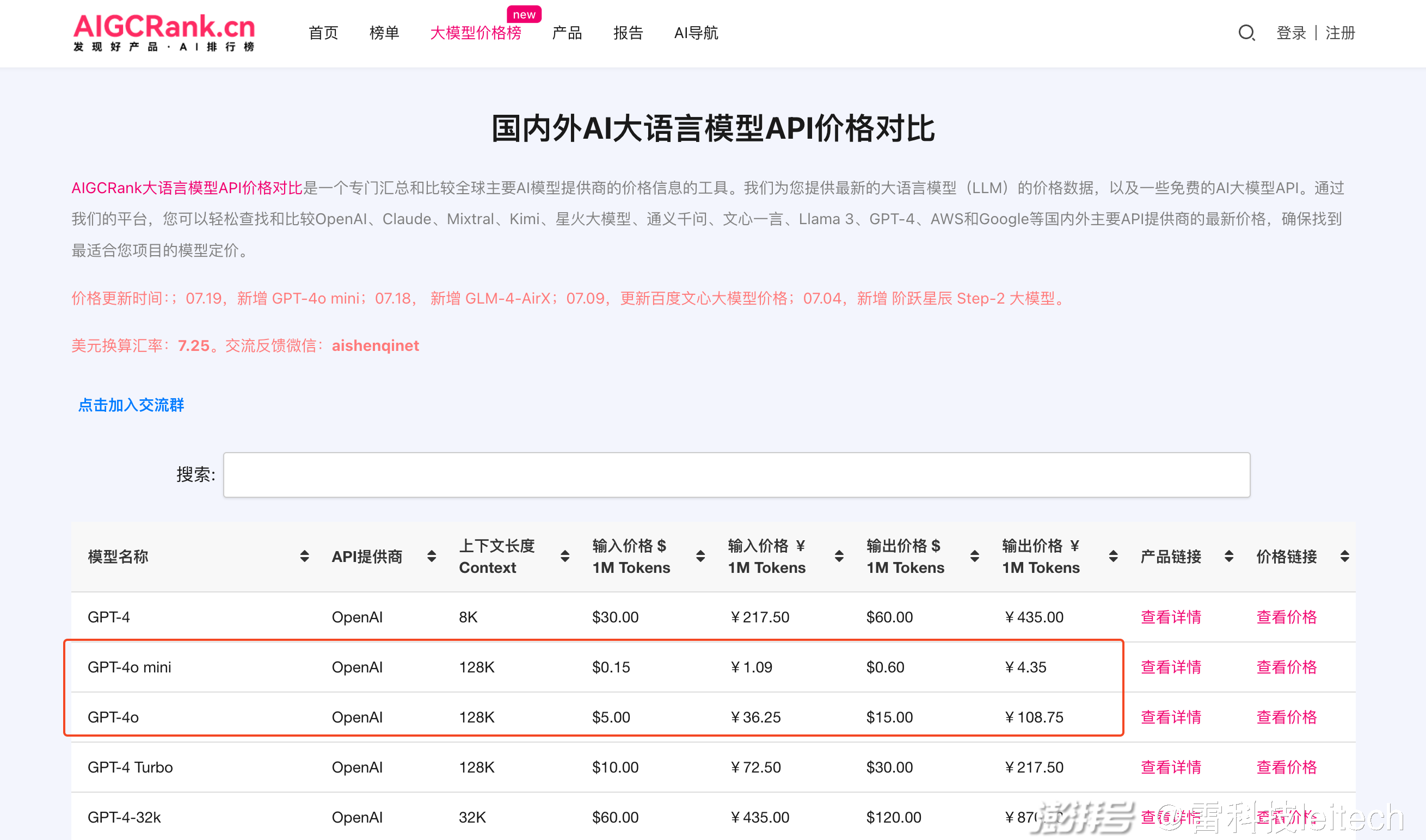
根據 AIGCRank 維護的《國內外 AI 大語言模型 API 價格對比》榜單:
- GPT-4o 每百萬個輸入 Token 的定價是 5 美元(人民幣約為 36.3 元),輸出是 15 美元(人民幣約為 109 元);
- 百度文心 4.0 Turbo 的定價是輸入 30 元、輸出 60 元;
- Claude 3 Haiku 的定價是輸入是 0.25 美元(人民幣約為 1.81 元)、輸出 1.25 美元(人民幣約為 9.08 元)。
價格差距,圖/雷科技
在確保性能滿足需求的前提下,Claude 3 Haiku 「小」模型的成本優勢,不言而喻。
被認為引起國內大模型集體降價的「始作俑者」DeepSeek(深度求索),在與 Gemini 1.5 Flash 綜合表現相近的情況下,API 定價(每百萬個)可以做到輸入 1 元、輸出 2 元。阿里通義千問的 Qwen-Long,甚至還做到了輸入 0.5 元、輸出 2 元。
對于開發者而言,「成本」和「效益」是大模型應用中最核心的兩點。而更低的大模型價格,無疑有助于更多企業和個人開發者在更多場景、更多應用中引入生成式 AI,也有助于 AI 在普通人生活、工作中的普及,正如 Oliver Parker 強調的:
我認為 GPT-4o Mini 真正體現了 OpenAI 讓 AI 更加普及的使命。如果我們希望 AI 惠及世界的每一個角落,每一個行業,每一個應用,我們必須讓 AI 更加實惠。
但更小的模型,夠用嗎?
在今年 4 月舉辦的百度 AI 開發者大會上,李彥宏指出,在一些特定場景中,經過精調后的小模型,它的使用效果可以媲美大模型。

圖/雷科技
隨后,阿里前技術副總裁賈揚清在朋友圈表示同意:「我覺得 Robin 這點說得非常對,在初始的應用嘗試過去之后,模型的特化會是一個從效果上和從性價比上更加 make sense 的選擇。」
這不只是國內大模型行業的共識。
「在整個互聯網上訓練出來的巨型大語言模型可能會嚴重大材小用。」網絡安全、內容分發和云計算公司 Akamai 的首席技術官 Robert Blumofe 表示,對于企業來說,「你并不需要一個知道《教父》所有演員、知道所有電影、知道所有電視節目的 AI 模型。」
簡單來說,大模型在朝著「通用化」的方向走了太遠,很多應用場景其實不需要大模型的「全能」。
而為了讓每一個參數都變得更有價值,大模型廠商還在一直研究更高效的蒸餾、剪枝等模型壓縮手段,試圖將大型語言模型的「知識」,更多地遷移到更小、更簡單的中小型語言模型中。
數據更是關鍵。

IEEE Spectrum,圖/雷科技
IEEE(電氣電子工程師學會)旗下雜志《IEEE 綜覽》援引專業學者指出,大型語言模型直接采用互聯網高度多樣化的海量文本進行訓練,但不管是微軟的 Phi 模型,還是蘋果 Apple Intelligent 中的模型,都是使用更豐富、更復雜的數據集來訓練,具有更一致的風格和更高的質量,也更容易學習。
打個比方,「大」模型相當于憑借著超高的記憶力和計算能力,在互聯網這個充斥各種高質量、低質量的「大染缸」中學習;而現在的「小」模型則是直接學習經過篩選、提煉的「教課書」,自然更容易學進去。
不過有意思的是,去年的時候行業更多認為,「小」模型真正的用武之地是在設備端,諸如智能手機、筆記本電腦等計算設備中,但更多廠商和開發者在云端還是更重視「大」模型。
但在過去幾個月,「小」模型還沒有在設備端真正火起來,也開始成為云端的趨勢所在。
究其根本,其實還是目前大模型在實際應用中「成本」與「效益」的不匹配,而「效益」還需要繼續摸索、嘗試的當下,「成本」就成了必須要解決的主要挑戰。
寫在最后
大模型不再「參數為王」。
在今年 4 月舉辦的 WIRED25(《連線》:改變世界的 25 人)活動上,OpenAI CEO 山姆·奧特曼(Sam Altman)表示,大模型的進步不會來自模型的更大化,「我認為我們正處在巨大模型時代的終結。」

圖/ OpenAI
某種程度上,山姆·奧特曼暗示了醞釀已久的 GPT-5 不會在參數上繼續擴大,而是通過算法或數據更進一步提高大模型的「智能」,從而通向 AGI(通用智能)。
至于剛剛推出的 GPT-4o mini,則是代表了另一條路徑,一條將 AI 更快普及到全世界的路徑。
但要走通這條路,最核心的問題就是在確保「效益」的同時,盡可能地降低「成本」,讓更多開發者用上 AI,用更具創意和實際價值的應用,讓更多用戶從中受益。
而這,可能也是國產廠商最擅長的。
2024上半年,科技圈風起云涌。
大模型加速落地,AI手機、AI PC、AI家電、AI搜索、AI電商……AI應用層出不窮;
Vision Pro開售并登陸中國市場,再掀XR空間計算浪潮;
HarmonyOS NEXT正式發布,移動OS生態生變;
汽車全面進入“下半場”,智能化成頭等大事;
電商競爭日益劇烈,卷低價更卷服務;
出海浪潮風起云涌,中國品牌邁上全球化征程;
……
7月流火,雷科技·年中回顧專題上線,總結科技產業2024上半年值得記錄的品牌、技術和產品,記錄過去、展望未來,敬請關注。

本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

