- +1
美國能源部百億億次超級計算機初探

除了HPE之外,還有誰愿意幫勞倫斯伯克利國家實驗室打造下一代NERSC-10超級計算機,還有橡樹嶺國家實驗室的未來OLCF-6超算系統?好的,微軟舉手了,還有亞馬遜云科技。收到,還有沒有其他感興趣的?
沒錯,現在情況大概就是這樣。
勞倫斯伯克利國家實驗室已經于9月15日就當前Perlmutter系統提出了技術升級邀約,橡樹嶺國家實驗室也緊隨其后,于9月27日就Frontier系統開放了技術升級招標。面對兩項需求,我們不禁好奇,美國能源部下屬的這些國家實驗室在采購下一代超級計算機時,具體有哪些選項可以考量?
英特爾已經不愿承包超級計算機業務,公司CEO Pat Gelsinger也清醒過來,不再討論在2027年之前實現Zettascale(即1000百億億次)算力的計劃。兩年之前,Gelsinger曾經對此信誓旦旦,但我們在計算之后發現,哪怕英特爾在2021年至2027年間每年都能把CPU和GPU性能提高一倍,也仍然需要11.6萬個節點加772兆瓦的能耗才能實現Zettascale。問題是這可能嗎?明顯不可能。
在經歷之前大型計算系統項目虧損之后,IBM也退出了這部分承包市場,開始專注沖擊以AI推理為核心的HPC工作負載。幾年之前,英偉達和Mellanox曾與IBM合作開發過百億億次系統,成果如今就坐落在勞倫斯利弗莫爾和橡樹嶺國家實驗室當中。但在此之后,英偉達發現AI訓練才是最來錢的道兒,所以不再像2008年到2012年那樣關注HPC模擬和建模。時至今日,哪怕英偉達的HPC業務規模再翻一番,小小的數字在如今生成式AI業務的爆發式增長當中,也只能作為可被舍去的小數點后部分。
Atos或者富士通也不可能向美國政府實驗室出售產品。戴爾倒是可以,但Michael Dell本人并不喜歡賠錢賺吆喝,所以幫得克薩斯大學搞的高性能計算項目已經足夠彰顯其愛國情懷,再多投入實無必要。
那市場上還有誰?沒錯,基本就是三大云巨頭——微軟、AWS和谷歌了。而根據最近的相關報道,他們也分別有著自己的問題。最大的問題就是這幫云服務商必須拿恐怖的設施規模吸引受眾,但客戶實際用得上的資源卻非常有限。無限容量、易于切換這些東西看似簡單,可在公有云端跟在國家級超級計算中心內的實現根本就不是一回事。后者需要把數千萬個并發核心連接起來以完成工作,同時輔以高帶寬、低延遲的網絡互連。與之相比,眾多小體量租戶各自使用有限資源的公有云業務簡直就像過家家。
勞倫斯伯克利國家實驗室、特別是旗下的國家能源研究科學計算中心,早在今年4月就要求各供應商提供NERSC-10超算的設計方案。下面來看技術文件中提出的開發路線圖:
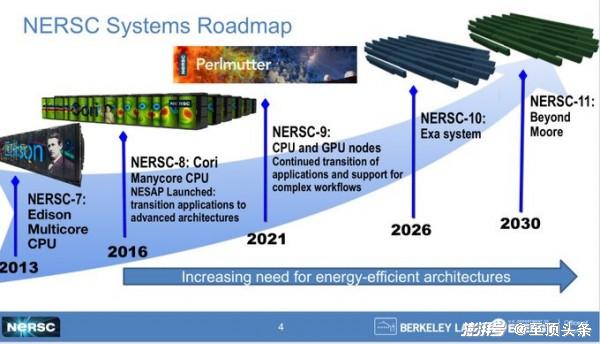
請注意,技術征求意見書跟真正的征求意見書不太一樣,前者更多是種預覽草案,希望初步定下盈虧基調來吸引更多廠商的參與。NERSC-10的正式征求意見書將于2024年2月5日發布,經過一段時間的質詢后最終在3月8日截止。早期訪問機器必須在2025年內交付,NERSC-10系統本體則須在2026年下半年交付,系統驗收(暨主承包商收款時間)預定在2027年之內。
與之對應,技術征求意見書則像是份長長的特性加功能清單,具體內容并不要求太過精確,因為勞倫斯伯克利實驗室也希望能對開放架構、復雜HPC和AI工作流程,以及各因素之間的相互匹配持開放態度。該實驗室先進技術小組負責人兼NERSC機器架構師Nick Wright在最近的HPC用戶論壇會議上發表演講,表示HPC技術、行業乃至整個社區都處于發展拐點,而核心影響因素一是摩爾定律的終結、二是AI技術的崛起。
NERSC-10的目標就是在HPC工作負載之上提供至少10倍于當前Perlmutter的性能。勞倫斯伯克利實驗室擁有一整套量子色動力學、材料、分子動力學、深度學習、基因組學和宇宙學應用程序,能夠準確衡量性能提升是否達到10倍。從其中的表述來看,只要最終大規模并行計算陣列能夠提供比CPU-GPU混合架構更好的算力和每瓦性能,那么所有國家實驗室都會快速跟進、采購相關設備來構建自己的數據中心。這樣的潛在收益,當然會令更多技術大廠為之心動。
四年之前,Hyperion曾表示NERSC-10的峰值性能將在8到12百億億次之間,而Frontier的峰值性能預計將在1.5到3百億億次之間。至于勞倫斯利弗莫爾的El Capitan,最終成績約在4到5百億億次左右。但NERSC-10的征求意見書不會公布峰值失敗率,所以我們無法判斷以上預測跟現實有多大出入。Wright還補充稱,勞倫斯伯克利實驗室也在努力擴大供應商群體,包括那些之前沒有就能源部征求意見書做出響應的供應商。
遺憾的是,NERSC-10目前的技術征求意見文件缺乏細節,唯一確定的就是擬議系統最大功耗不可超過20兆瓦,且最大占地面積不可超過4784平方英尺。此外,NERSC也對能源效率非常重視,考慮到狹小空間內極高的發熱密度,相關設備必然需要采用水冷(與Perlmutter一樣)。
橡樹嶺國家實驗室坐落于伯克利大學正東偏南約2466英里外的田納西州荒山當中。在這里,OLCF-6系統的技術征求意見書也已出爐,向HPE及其他有意參與的競爭對手提出了挑戰。
下圖所示為2019年時公布的舊路線圖,點明了Frontier及其后續系統的發展方向:
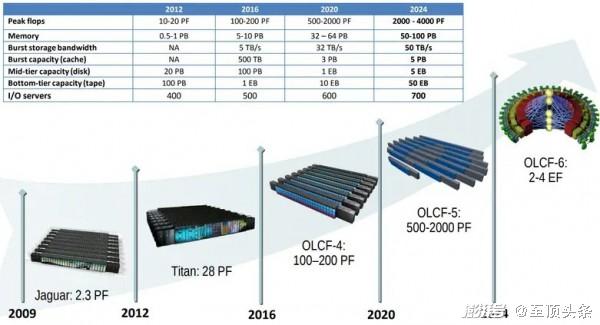
“Summit”OLCF-4機器已經成功達成了性能目標上限,而Frontier OLCF-5機器只能說是幾乎接近上限。如果把系統的實際發布時間均取中間值,則OLCF-4和OLCF-5相當于分別在2018年和2022年交付,OLCF-6則預計在2027年。但實際上“Jaguar”系統是在2009年交付的,“Titan”系統則是2012年,所以猜測這里標出的時間其實就是相應超算系統的實際發布時間。
這也不要緊,畢竟每家廠商的HPC路線圖都有延后。預計未來十年在摩爾定律走入困境的大背景之下,技術承諾無法實現將成為一種常態。
無論如何,當時的路線圖預計OLCF-6的峰值性能應該是在2到4百億億次,最樂觀的估計就是在4百億億次。而根據目前的技術征求意見文件來看,Frontier將于2028年迎來其生命周期終點,就是說在此之前(也就是2027年),OLCF-6必須準備就位。橡樹嶺實驗室愿意接受Frontier升級、全新系統設計以及其他場外系統投標——我們認為,最后一點就是在向超大規模基礎設施運營商和云服務商伸出橄欖枝。橡樹嶺還對并行文件系統和AI優化型存儲系統敞開了懷抱(指向的應該是DataDirect Networks和Vast Data)。
對了,順帶一提,如果Frontier的繼任者沒有部署在田納西州,則中標方還須繳納9.75%的銷售稅。這就是美國東部諾克斯維爾數據中心專區的規矩……
無論后續機型是什么,它都必須匹配橡樹嶺數據中心4300平方英尺的物理面積,且不可超過30兆瓦的功耗上限。目前還未公布應用性能目標,但OLCF-6基準測試套件中的應用程序列表(包括LAMMPS、M-PSNDS、MILC、QMCPACK、SPATTER、FORGE 和 Workflow)已經涵蓋各類HPC模擬和AI訓練方面的NERSC-10基準套件。
很難想象,除了HPE之外還有誰會愿意參與這場競標,但政府項目要求至少要有兩家參與競標的廠商。如果實在沒有,可能就得生生“創造”一個。
真正的拐點和由此引發的問題在于,專門設計本地系統的HPE到底能不能在這兩筆交易中擊敗微軟或AWS。云服務商必然采用跟傳統云業務截然不同的方法——更多類似于托管業務,借此在HPC和AI工作負載上提供更好的性能。而即便如此,恐怕也只有他們才參與競標的能力、完成工作的資金儲備、以及沖擊百億億次的實力。
唯一的問題就是,他們肯定不會像之前的SGI、IBM、英特爾和HPE那樣接受更低的構建成本。這才是真正的難題所在,畢竟如今的AMD已經不會再像Frontier和El Capitan項目那樣用CPU和GPU項目從美國政府手中換取特殊利益。美國政府當然可以用免于起訴和允許壟斷等特權換取廉價的HPC/AI超級計算機,但至少我們還沒聽說過如此大膽的交換條件,所以新一代超算的命運仍是個未定之數。
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

