- +1
英偉達(dá)GH200首次亮相AI性能基準(zhǔn)評測,比H100性能提升17%
·英偉達(dá)GH200 Grace Hopper超級芯片首次亮相影響力最廣的國際AI性能基準(zhǔn)評測——MLPerf行業(yè)基準(zhǔn)測試。在此次測試中, GH200每芯片性能優(yōu)勢比H100 GPU高出17%。
·為提高大型語言模型(LLM)的推理性能,英偉達(dá)推出一款能夠優(yōu)化推理的生成式AI軟件——TensorRT-LLM,其能夠在不增加成本的情況下將現(xiàn)有H100 GPU的推理性能提升兩倍以上。
當(dāng)?shù)貢r間9月11日,推出不到兩個月的英偉達(dá)GH200 Grace Hopper超級芯片首次亮相MLPerf行業(yè)基準(zhǔn)測試。在此次測試中,具有更高的內(nèi)存帶寬和更大的內(nèi)存容量的GH200與H100 GPU相比,性能高出17%。
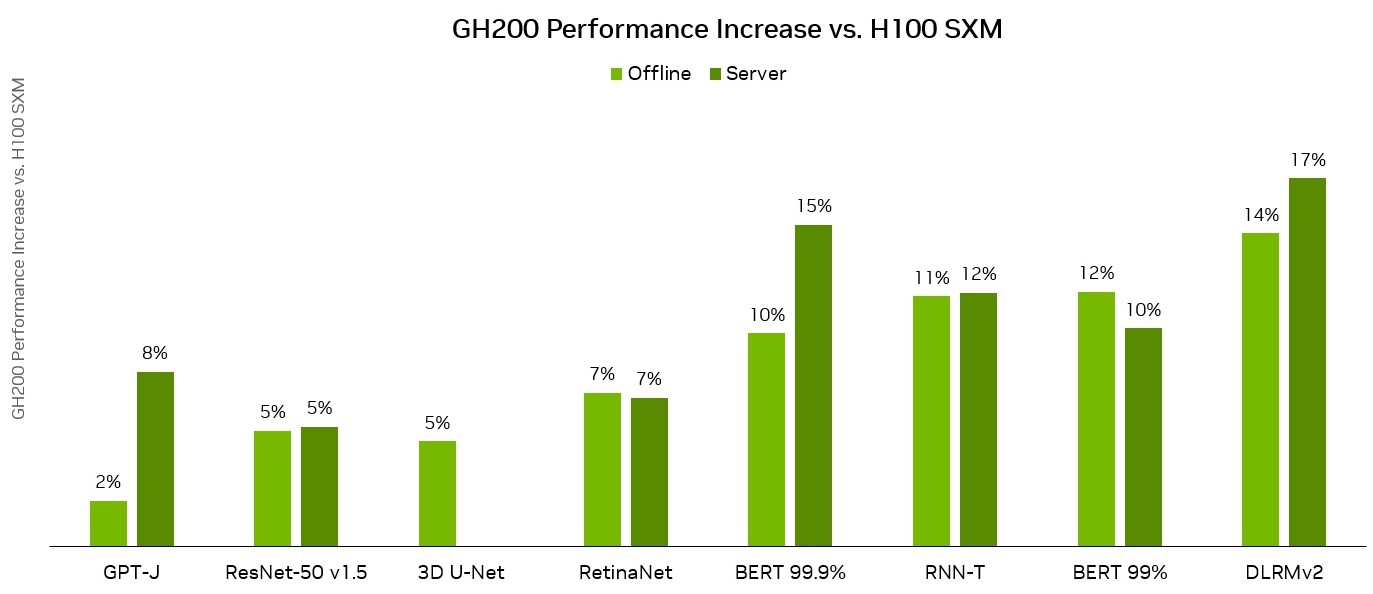
Grace Hopper與DGX H100 SXM在MLPerf推理數(shù)據(jù)中心性能結(jié)果的比較。來源:英偉達(dá)
在新聞發(fā)布會上,英偉達(dá)人工智能總監(jiān)戴夫·薩爾瓦托(Dave Salvator)表示:“Grace Hopper表現(xiàn)出色,首次提交的性能比H100 GPU性能高出多達(dá)17%,而我們的H100 GPU產(chǎn)品已經(jīng)在各個領(lǐng)域取得了領(lǐng)先地位。”
MLPerf是影響力廣泛的國際AI性能基準(zhǔn)評測,其推理性能評測涵蓋使用廣泛的六大AI場景,比如計算機(jī)視覺、自然語言處理、推薦系統(tǒng)、語音識別等,每個場景采用最主流的AI模型作為測試任務(wù),每一任務(wù)又分為數(shù)據(jù)中心和邊緣兩類場景。其由MLCommons(由來自學(xué)術(shù)界、研究實(shí)驗(yàn)室和行業(yè)的人工智能領(lǐng)導(dǎo)者組成的聯(lián)盟)開發(fā),旨在對硬件、軟件和服務(wù)的訓(xùn)練和推理性能“構(gòu)建公平和有用的基準(zhǔn)測試”。
此次MLPerf Inference v3.1基準(zhǔn)測試是繼4月發(fā)布3.0版本之后的又一次更新,值得注意的是,這次更新包含了兩個第一次:引入基于60億參數(shù)大語言模型GPT-J的推理基準(zhǔn)測試(AI模型的大小通常根據(jù)它有多少參數(shù)來衡量)和改進(jìn)的推薦模型。
GPT-J是來自EleutherAI的OpenAI GPT-3的開源替代品,現(xiàn)已在MLPerf套件中用作衡量推理性能的基準(zhǔn)。與一些更先進(jìn)的人工智能模型(如1750億參數(shù)的GPT-3)相比,60億參數(shù)的GPT-J屬于相當(dāng)輕量的模型,但它非常適合推理基準(zhǔn)的角色。該模型總結(jié)了文本塊,并可在延遲敏感的在線模式和吞吐量密集型的離線模式下運(yùn)行。
GH200 Grace Hopper超級芯片在GPT-J工作負(fù)載方面取得了優(yōu)異的成績,在離線和服務(wù)器場景中的每加速器性能都達(dá)到了最高水平。據(jù)英偉達(dá)介紹,GH200 Grace Hopper超級芯片是專為計算和內(nèi)存密集型工作負(fù)載而設(shè)計,它在最苛刻的前沿工作負(fù)載上提供了更高的性能,如基于Transformer的大型語言模型(具有數(shù)千億或數(shù)萬億參數(shù))、具有數(shù)萬億字節(jié)嵌入表的推薦系統(tǒng)和矢量數(shù)據(jù)庫。
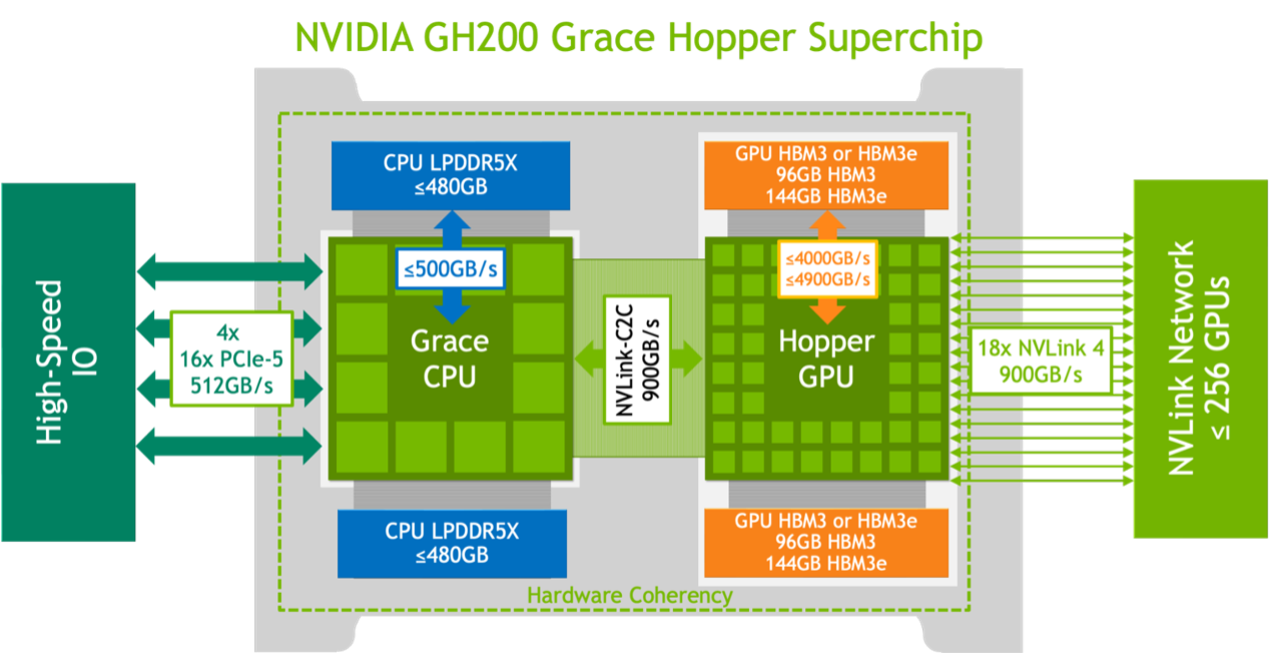
GH200 Grace Hopper 超級芯片的邏輯概述。來源:英偉達(dá)
GH200超級芯片最新版由英偉達(dá)CEO黃仁勛在8月的世界頂級計算機(jī)圖形學(xué)會議SIGGRAPH上公布。之所以稱其為超級芯片,因?yàn)樗谕粔K板上將英偉達(dá)Grace中央處理單元(CPU)和Hopper圖形處理單元(GPU)連接在一起。借助新型雙GH200服務(wù)器中的NVLink,系統(tǒng)中的CPU和GPU將通過完全一致的內(nèi)存互連進(jìn)行連接。這種組合提供了更大內(nèi)存、更快帶寬,能夠在CPU和GPU之間自動切換計算所需要的資源,????實(shí)現(xiàn)性能最優(yōu)化。
薩爾瓦托說:“如果GPU非常忙碌,而CPU相對空閑,我們可以將功率預(yù)算轉(zhuǎn)移到GPU上,以允許它提供額外的性能。通過擁有這個功率余地,我們可以在整個工作負(fù)載中保持更好的頻率駐留,從而提供更多的性能。”
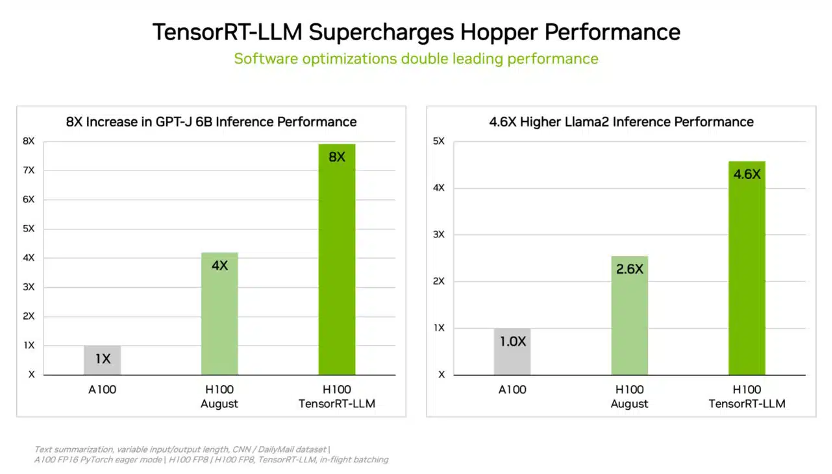
TensorRT-LLM能夠在不增加成本的情況下將現(xiàn)有H100 GPU的推理性能提升兩倍以上。來源:英偉達(dá)
此外,為提高大型語言模型(LLM)的推理性能,英偉達(dá)推出一款能夠優(yōu)化推理的生成式AI軟件——TensorRT-LLM,其能夠在不增加成本的情況下將現(xiàn)有H100 GPU的推理性能提升兩倍以上。重要的是,該軟件可以實(shí)現(xiàn)這種性能改進(jìn),而無需重新訓(xùn)練模型。
英偉達(dá)稱,由于時間原因,TensorRT-LLM沒有參加8月的MLPerf提交。據(jù)英偉達(dá)的內(nèi)部測試,在運(yùn)行60億參數(shù)GPT-J模型時,相較于沒有使用TensorRT-LLM的上一代GPU,在H100 GPU上使用TensorRT-LLM能夠?qū)崿F(xiàn)8倍的性能提升。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯(lián)網(wǎng)新聞信息服務(wù)許可證:31120170006
增值電信業(yè)務(wù)經(jīng)營許可證:滬B2-2017116
? 2014-2025 上海東方報業(yè)有限公司

