- +1
詳解AI加速器(一):2012年的AlexNet到底做對了什么?
選自 Medium
作者:Adi Fuchs
機器之心編譯
AI、機器學習、深度學習的概念可以追溯到幾十年前,然而,它們在過去的十幾年里才真正流行起來,這是為什么呢?AlexNet 的基本結構和之前的 CNN 架構也沒有本質區別,為什么就能一鳴驚人?在這一系列文章中,前蘋果、飛利浦、Mellanox(現屬英偉達)工程師、普林斯頓大學博士 Adi Fuchs 嘗試從 AI 加速器的角度為我們尋找這些問題的答案。
當代世界正在經歷一場革命,人類的體驗從未與科技如此緊密地結合在一起。過去,科技公司通過觀察用戶行為、研究市場趨勢,在一個通常需要數月甚至數年時間的周期中優化產品線來改進產品。如今,人工智能已經為無需人工干預就能驅動人機反饋的自我改進(self-improving)算法鋪平了道路:人類體驗的提升給好的技術解決方案帶去獎勵,而這些技術解決方案反過來又會提供更好的人類體驗。這一切都是在數百萬(甚至數十億)用戶的規模下完成的,并極大地縮短了產品優化周期。
人工智能的成功歸功于三個重要的趨勢:1)新穎的研究項目推動新的算法和適用的用例;2)擁有收集、組織和分析大量用戶數據的集中式實體(例如云服務)的能力;3)新穎的計算基礎設施,能夠快速處理大規模數據。
在這個系列的文章中,前蘋果、飛利浦、Mellanox(現屬英偉達)工程師、普林斯頓大學博士 Adi Fuchs 將重點關注第三個趨勢。具體來說,他將對 AI 應用中的加速器做一個高層次的概述——AI 加速器是什么?它們是如何變得如此流行的?正如在后面的文章中所討論的,加速器源自一個更廣泛的概念,而不僅僅是一種特定類型的系統或實現。而且,它們也不是純硬件驅動的。事實上,AI 加速器行業的大部分焦點都集中在構建穩健而復雜的軟件庫和編譯器工具鏈上。
以下是第一部分的內容,其余部分將在后續的文章中更新。
人工智能不僅僅是軟件和算法
AI / 機器學習 / 深度學習的概念可以追溯到 50 多年以前,然而,它們在過去的十幾年里才真正流行起來。這是為什么呢?
很多人認為,深度學習的復興始于 2012 年。當時,來自多倫多大學的 Alex Krizhevsky、Ilya Sutskever、Geoffrey Hinton 等人提出了一個名為「AlexNet」的深度神經網絡并憑借該網絡贏得了 2012 年大規模視覺識別挑戰賽的冠軍。在這場比賽中,參賽者需要完成一個名叫「object region」的任務,即給定一張包含某目標的圖像和一串目標類別(如飛機、瓶子、貓),每個團隊的實現都需要識別出圖像中的目標屬于哪個類。
AlexNet 的表現頗具顛覆性。這是獲勝團隊首次使用一種名為「卷積神經網絡(CNN)」的深度學習架構。由于表現過于驚艷,之后幾年的 ImageNet 挑戰賽冠軍都沿用了 CNN。這是計算機視覺史上的一個關鍵時刻,也激發了人們將深度學習應用于其他領域(如 NLP、機器人、推薦系統)的興趣。
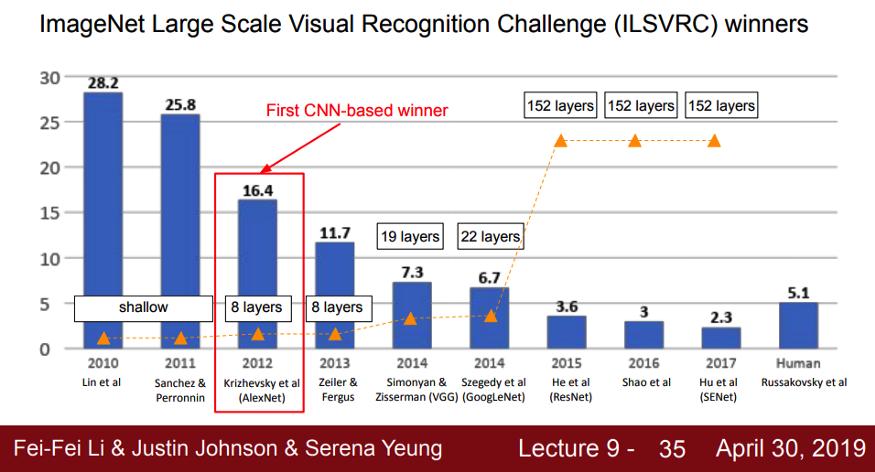
ImageNet 挑戰賽冠軍團隊的分類錯誤率逐年變化情況(越低越好)。
有意思的是,AlexNet 的基本結構和之前那些 CNN 架構并沒有太大區別,比如 Yann LeCun 等人 1998 年提出的 LeNet-5。當然,這么說并不是想抹殺 AlexNet 的創新性,但這確實引出了一個問題:「既然 CNN 不是什么新東西,AlexNet 的巨大成功還可以歸因于哪些要素呢?」從摘要可以看出,作者確實使用了一些新穎的算法技術:
「為了加速訓練,我們用到了非飽和神經元和一個非常高效的 GPU 卷積操作實現。」
事實證明,AlexNet 作者花了相當多的時間將耗時的卷積操作映射到 GPU 上。與標準處理器相比,GPU 能夠更快地執行特定任務,如計算機圖形和基于線性代數的計算(CNN 包含大量的此類計算)。高效的 GPU 實現可以幫他們縮短訓練時間。他們還詳細說明了如何將他們的網絡映射到多個 GPU,從而能夠部署更深、更寬的網絡,并以更快的速度進行訓練。
拿 AlexNet 作為一個研究案例,我們可以找到一個回答開篇問題的線索:盡管算法方面的進展很重要,但使用專門的 GPU 硬件使我們能夠在合理的時間內學習更復雜的關系(網絡更深、更大 = 用于預測的變量更多),從而提高了整個網絡的準確率。如果沒有能在合理的時間框架內處理所有數據的計算能力,我們就不會看到深度學習應用的廣泛采用。
如果我是一名 AI 從業者,我需要關心處理器嗎?
作為一名 AI 從業者,你希望專注于探索新的模型和想法,而不希望過多擔心看起來不相關的問題,如硬件的運行方式。因此,雖然理想的答案是「不,你不需要了解處理器」,但實際的答案是「可能還是要了解一下」。如果你非常熟悉底層硬件以及如何調試性能,那么你的推理和訓練時間就會發生變化,你會對此感到驚訝。
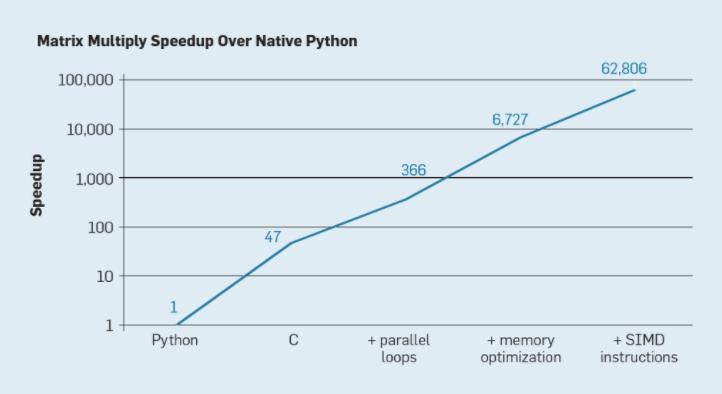
各種并行化技術對于矩陣乘法的加速效果。
如果不懂硬件,你所花的時間可能會多 2-3 倍,有時甚至多一個數量級。簡單地改變做矩陣乘法的方式可能幫你收獲巨大的性能提升(或損失)。性能欠佳可能會影響你的生產力以及你可以處理的數據量,并最終扼殺你的 AI 周期。對于一家大規模開展人工智能業務的企業來說,這相當于損失了數百萬美元。
那么,為什么不能保證得到最佳性能呢?因為我們還沒有有效地達到合理的「user-to-hardware expressiveness」。我們有一些有效利用硬件的用例,但還沒泛化到「開箱即用」的程度。這里的「開箱即用」指的是在你寫出一個全新的 AI 模型之后,你無需手動調整編譯器或軟件堆棧就能充分利用你的硬件。

AI User-to-Hardware Expressiveness。
上圖說明了「user-to-hardware expressiveness」的主要挑戰。我們需要準確地描述用戶需求,并將其轉換成硬件層(處理器、GPU、內存、網絡等)能夠理解的語言。這里的主要問題是,雖然左箭頭(programming frameworks)主要是面向用戶的,但將編程代碼轉換為機器碼的右箭頭卻不是。因此,我們需要依靠智能的編譯器、庫和解釋器來無縫地將你的高級代碼轉換為機器表示。
這種語義鴻溝難以彌合的原因有兩個:
1)硬件中有豐富的方法來表達復雜的計算。你需要知道可用的處理元素的數量(如 GPU 處理核心)、你的程序需要的內存數量、你的程序所展示的內存訪問模式和數據重用類型,以及計算圖中不同部分之間的關系。以上任何一種都可能以意想不到的方式對系統的不同部分造成壓力。為了克服這個問題,我們需要了解硬件 / 軟件堆棧的所有不同層是如何交互的。雖然你可以在許多常見的場景中獲得良好的性能,但現實中還有無盡的長尾場景,你的模型在這些場景中可能表現極差。
2)雖然在計算世界中,軟件是慢的,硬件是快的,但部署世界卻在以相反的方式運行:深度學習領域正在迅速變化;每天都有新的想法和軟件更新發布,但構建、設計和試生產(流片)高端處理器需要一年多的時間。在此期間,目標軟件可能已經發生了顯著的變化,所以我們可能會發現處理器工程師一年前的新想法和設計假設已經過時。
因此,你(用戶)仍然需要探索正確的方法來識別計算耗時瓶頸。為此,你需要了解處理器,特別是當前的 AI 加速器,以及它們如何與你的 AI 程序交互。
原文鏈接:https://medium.com/@adi.fu7/ai-accelerators-part-i-intro-822c2cdb4ca4
使用Python快速構建基于NVIDIA RIVA的智能問答機器人
NVIDIA Riva 是一個使用 GPU 加速,能用于快速部署高性能會話式 AI 服務的 SDK,可用于快速開發語音 AI 的應用程序。Riva 的設計旨在輕松、快速地訪問會話 AI 功能,開箱即用,通過一些簡單的命令和 API 操作就可以快速構建高級別的對話式 AI 服務。
2022年1月26日19:30-21:00,最新一期線上分享主要介紹:
對話式 AI 與 NVIDIA Riva 簡介
利用NVIDIA Riva構建語音識別模塊
利用NVIDIA Riva構建智能問答模塊
利用NVIDIA Riva構建語音合成模塊
原標題:《詳解AI加速器(一):2012年的AlexNet到底做對了什么?》
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

