- +1
智能體如何自己學會在多車環境下開車?研究還用了GTA5
如何在有其他車輛參與的環境中讓智能體(agent)學會自動駕駛的策略?這是一個復雜的問題,涉及感知、控制和規劃多個層面。
在今年西安舉辦的機器人領域頂級會議國際機器人和自動化會議(International Conference of Robotics and Automation, ICRA)上,來自于美國卡內基梅隆大學(曹金坤)、加州大學伯克利分校(Xin Wang, Trevor Darrell)和瑞士蘇黎世聯邦理工大學(Fisher Yu)的研究人員發表了題為《instance-aware predictive navigation in multi-agent environments》(多智能體環境下的實例預測導航)的研究。
研究提出實例感知預測控制( IPC,Instance-Aware Predictive Control)方法,強調在不添加任何的人為示范(Expert demonstration,常用于“模仿學習”中的策略優化)前提下,從無到有,完全通過強化學習中“探索-評估-學習”(explore-evaluate-learn)的路線進行策略的學習,提供了更好的可解釋性和樣本效率。
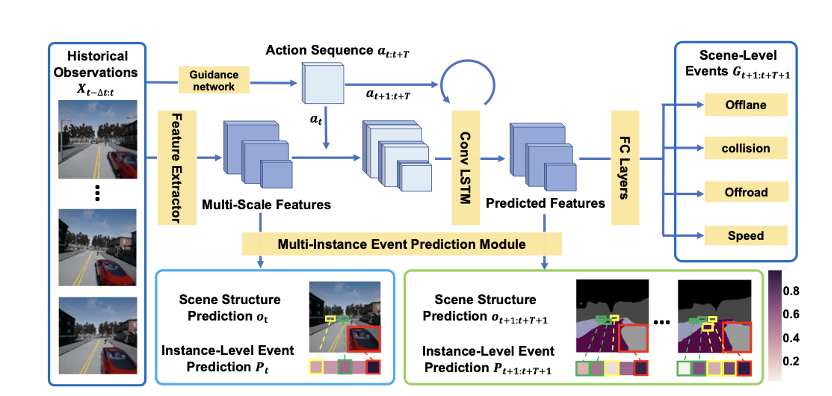
實例感知預測控制(IPC)框架。在給定歷史觀察情況下,引導網絡(Guidance network)有助于在動作空間中對動作序列進行采樣。該模型既預測未來的視覺結構,也包含某些事件的可能性。Observation是包含語義分割和實例(其他智能體車輛)位置的視覺觀察。G是場景級事件。P是每個預測的可能實例位置上的實例級事件。事件預測給動作選擇帶來了參考。視覺結構預測為動作決策帶來解釋。右下角的顏色條表示實例級事件的概率。
強化學習方法:從無到有,無人為示范學會自動駕駛策略
在回答此研究的亮點之處時,論文第一作者、卡內基梅隆大學在讀博士曹金坤對澎湃新聞(www.usamodel.cn)記者表示,“我們在具有挑戰性的CARLA(Car Learning to Act,開源模擬器,可模擬真實的交通環境,行人行為,汽車傳感器信號等)多智能體駕駛模擬環境中建立了無需人為示范(Expert demonstration)的算法框架,提供了更好的可解釋性和樣本效率。”
當前的自動駕駛的策略更多的基于規則(rule-based):通過人設計具體的策略來進行駕駛。也有很多學者基于“模仿學習”(imitation learning)的方法進行研究,即讓車輛模仿人在不同的情況下的駕駛選擇。
曹金坤表示,“這兩種方法都有弊端,前者是人難免‘百密一疏’,有些具體的場景無法被規則很好地覆蓋,或者在進行設置時很多衡量的指標都難以具有普遍性。后者的問題在于,車輛只能學習人類好的、安全場景下的駕駛策略,而一旦現實場景中的自動駕駛車輛進入了危險的、在學習時人沒有作出示范的場景,它的策略就變成完全空白了。”
“而相比較這兩個方法,強化學習(Reinforcement learning)因為基于車輛的探索,所以可以更普遍地讓車輛嘗試和探索到不同的場景,相較于前兩種方法有其優勢。而如果我們之后希望可以有大規模、更加健壯的自動駕駛策略開發的流水線(pipeline),這種基于探索的策略或許至少會有一種有益的補充。”
完成這個強化學習過程的一個重要基礎就是數據采集,從視覺場景直接獲得原始數據(如相機觀察數據等)進行強化學習一直是一個困難的問題,這也導致了“基于原始數據”(raw-data-based)的強化學習要比“基于狀態”(state-based,指智能體通過人為定義的干凈的狀態描述來進行策略的開發)的強化學習進展緩慢得多。
研究團隊為了切合現實的自動駕駛策略的真實性要求,使用了基于原始數據的方法,并且只使用了車前的一個無深度攝像頭的數據,沒有使用任何的雷達設備。基于這個唯一的傳感器,被控制的車輛會對場景中的其他車輛進行檢測。

緊接著,通過采樣的方法,智能體會選取多組動作序列的候選,并對不同的行動策略已經結果預測,判斷采取這個策略在未來一段時間內可能造成的影響。基于這種對未來預測并檢驗的過程,智能體(agent)學習到正確的駕駛方式,模型預測控制才成為可能。
對未來的預測:“稀疏”與“稠密”的信號
在預測階段,盡管理想地預測和駕駛相關的指標對于控制來說已經是足夠的了,如和其他車輛碰撞的概率、車輛行駛到反向車道的概率等等。但是在完全基于車輛自身感知和復雜真實的物理環境中,這種非常簡單的信號被認為是過于“稀疏”(sparse)的,無法支撐起復雜模型的訓練所需的數據規模。
為了獲取更加“稠密”的模型訓練數據來源,研究者使用了計算機視覺中的“語義分割掩碼”(semantic segmentation mask,即觀察范圍內不同類別物體的輪廓)來幫助訓練。而此類人類可以理解的視覺數據又反過來幫助人們理解智能體所做的動作選擇,比如在未來某時刻其預測有其他車輛會非常靠近自己的右側,那么這時如果其輸出的駕駛動作是向左傾斜也可以被理解了。
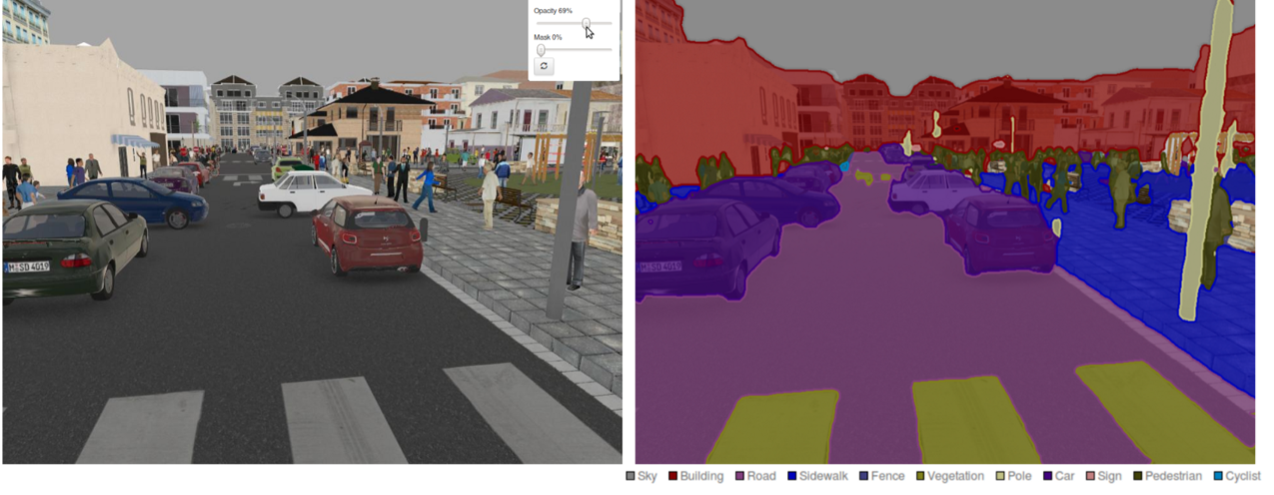
道路場景下的語義分割掩碼示意圖
所有前述的未來場景的視覺(車輛位置,語義分割掩碼)和狀態(碰撞幾率、逆行的機會等)都被控制車輛在模擬器中行駛的同時收集下來,然后放在一個緩沖區(buffer)中。在駕駛收集數據的同時,這個智能體會從緩沖區中采樣歷史的駕駛記錄,來進行視覺感知和狀態預測模型的訓練。整個模型的訓練和策略演化都是完全在線(online)和無人為示范(demonstration-free)的,即在線的強化學習(online reinforcement learning)。
“讓智能體在有其他車輛參與的環境中學會自動駕駛策略有兩個部分,場景感知與預測,以及基于此的駕駛策略選擇。在場景感知與預測中,一個是智能體對于周邊的建筑、車道等靜止的物體要做出非常精準的未來狀態估計,另一個是對于其他的車輛的未來狀態做出準確估計,后者要難得多,”曹金坤對澎湃新聞表示。
“因此,盡管在長久的訓練后,智能體對于周邊的建筑、車道等靜止的物體可以做出非常精準的未來狀態估計,但是對于其他的車輛的未來狀態還是會非常的撓頭,”曹金坤表示。
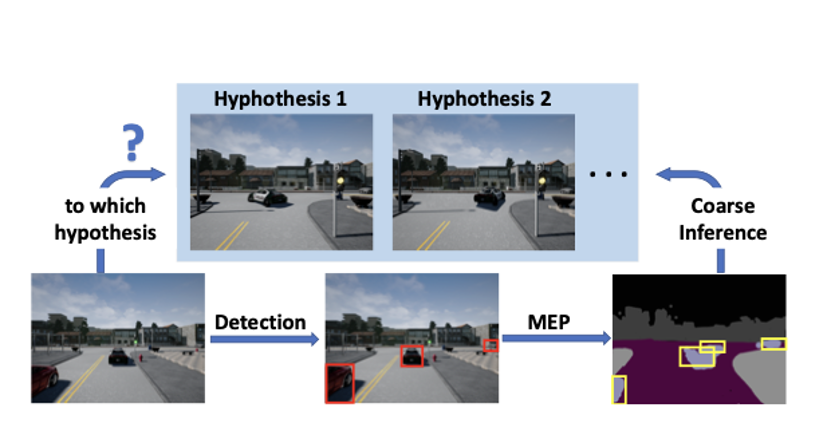
多實例事件預測(Multi-instance Event Prediction,MEP)中可能的實例位置的預測如何為不同的假設建立粗略的推理。
論文中提出,在駕駛中,其他車輛的策略是未知的,受控的智能體對他們的策略沒有預先的感知,而且他們的動作也有一定的隨機性,不是一個完全的“決定性”(deterministic)的動態過程(dynamic process),受控車輛面對的實際上是“多假設未來”(multi-hypothesis future),也就是說從現在的時間點出發,即使受控車輛一直采取一樣的行動,未來的整個道路情況都依舊是不確定的。
“為了解決這個問題,我們設計去預測未來的狀態分布,而不是單一可能。但是從根本上說,這種方法受限于模型的遺忘和從有限數據采樣預測分布的困難等問題,做的還是不夠好的,需要進一步的改進,”曹金坤反思道。
利用預測結果進行自動駕駛策略的選擇
在擁有預測未來場景和車輛狀態的能力之后,研究團隊還需要解決駕駛動作的采樣和評估問題。
研究團隊對這兩個階段分別設計了解決方案。
第一個困難便是在連續的動作空間中進行采樣(比如踩油門的力度和方向盤的角度都是連續的數字)。對此研究團隊設計了一個“指導網絡”(guidance network),其在連續的動作空間中首先進行離散化處理,通過當前和過去的場景觀測在離散化后的空間中選擇一個決策子區域,然后在這個選中的更小的動作區域中進行均勻采樣得到最后的動作信息。
對于采樣動作的評估困難的問題,其主要來自于對于未來其他車輛狀態預測中的高噪聲,而這種噪聲又源自于前述的“多假設未來”。針對這個問題,研究團隊設計了兩階段的(two-stage)損失函數(cost function)計算和候選過濾幾率。
在第一個階段中,通過計算一個與其他車輛不直接相關的未來狀態產生的損失來過濾掉一部分采樣出的候選動作。之后在第二個階段中,單純對于在未來與其他車輛碰撞的幾率,得到s*p*c的損失數值,其中s是一個折扣系數,目的是令距離當前越遠的未來狀態對于當前的決策影響越小,使得車輛可以優先專注于即將發生的危險,p是對于這個狀態預測的信度(confidence)估計,c是和目標車輛產生碰撞的概率估計。通過這種與其他車輛相關(instance-aware)的損失計算,智能體最終選中了要被執行的駕駛動作。
自動駕駛研究中的局限:模擬環境與損失函數設計
在采訪中,曹金坤非常坦誠地談及這篇論文中方法的局限性和缺陷。曹金坤提醒,“受限于成本、法律等障礙,當前類似的實驗都只能在模擬環境下進行,而這就對模擬環境的真實性提出了很高要求。而在如今的物理、數值計算、圖形學等領域的發展狀態下,我們還不可能有一個和現實場景一模一樣的模擬環境,這就對開發策略在真實場景中的可用性帶來了一些隱患。如果之后有了更加真實的模擬器乃至于‘元宇宙’,這個問題或許可以被緩解一些。”
同時,“我們的方法還基于人手工的損失函數的設計,這個問題也是現在的模型預測控制的一個幾乎共有的問題,這個損失函數設計的好壞類似于強化學習中的獎勵函數(reward function)的好壞一樣,都會對方法的效果產生很大的影響,但是因為設計開發者自身的知識、場景狀態簡化的可行性等,都不可能是最完美的,所以我們希望這個領域可以有一個更好的“適應性”(adpative)或者自學習的損失/獎勵函數的方法出現,在不同的場景和需求下使用不同的約束函數。但是這又變成了一個雞生蛋還是蛋生雞的問題,現在來看還是非常的困難,”曹金坤補充道。
商用的完全的自動駕駛離我們還有多遠?
面對商用的完全的自動駕駛什么時候能替代人類上路開車的疑問,曹金坤表示,“很多問題,特別是技術問題,為了讓公眾了解,方便傳播,往往會被過分的簡化。比如‘商用的完全的自動駕駛’怎么定義呢?我們現在常說L1-L5,但是這個也是有問題的。如果我們討論的是科幻中那種完全移除了駕駛座,道路上100%都是自動駕駛車輛在駕駛的話,我覺得技術上可能只需要10年,事故率就可以低于現在的人駕駛的事故率了,但是考慮到相關的法律、就業等問題,我覺得這個周期會長的多。”
“另外,如果這些車輛可以互相的分享信息,他們不是所謂的獨立智能體的話,這個事情在技術上會更快一些。但是,如果不是100%的自動駕駛車輛,而是人和自動駕駛車輛混合的話,問題就變得復雜的多了,在法律上和技術上都是如此,我很難去預測這個事情了,我覺得也不可能有人可以預測。”
附:
研究中采用的CARLA模擬器和游戲俠盜獵車5(GTA5)
因為成本和可行性原因,現有的給予強化學習的自動駕駛策略都基于一些仿真模擬器進行,該文章方法基于英特爾團隊開發的CARLA模擬器和著名的游戲俠盜獵車5(GTA5)進行。

CARLA模擬器中的道路場景

GTA V游戲中的駕駛場景
CARLA基于著名的虛幻5物理引擎,在物理仿真和場景真實度上相對于之前的同類產品都有很大的提升,而且因為其被設計的最初目的便是進行相關的研究和工程模擬,所以提供了完整的編程控制接口,可以進行自由的定制操作。
而GTA V是電子游戲俠盜獵車的最新作,在發布接近十年后仍舊擁有最優秀的視覺真實度和開放的場景設計,但是美中不足的是其作為一個游戲并不自帶任何的編程控制接口,所以研究人員使用了一些外掛的控制腳本來進行自動駕駛車輛在游戲內的操作以及對其狀況的分析。
澎湃新聞:請問做這樣一個研究的初衷是什么?
曹金坤:現在自動駕駛的策略更多的基于規則(rule-based),也就是通過人手工設計的策略來進行駕駛。而在學術界中,很多人研究基于“模仿學習”(imitation learning)的方法,也就是讓讓車輛模仿在不同的情況下人的駕駛選擇。但是這兩種方法都有弊端,前者是人難免“百密一疏”,有些具體的場景無法被很好的規則覆蓋,或者在進行設置的時候很多衡量的指標都難以具有普遍性。后者的問題在于,車輛只能學習人的好的、在安全場景下的駕駛策略,而一旦現實場景中的自動駕駛車輛進行了危險的、在學習時人沒有作出示范的場景,他的策略就變成完全空白了。而相比較這兩個方法,強化學習因為基于車輛的探索,所以可以更普遍地讓車輛嘗試和探索到不同的場景,相較于前兩種方法有他的優勢。而如果我們之后希望可以有大規模的、更加健壯的自動駕駛策略開發的流水線(pipeline),這種基于探索的策略或許至少會有一種有益的補充。
澎湃新聞:您覺得這個研究還有什么不足?
曹金坤:坦白地說,這個工作只能說是在前述的方向上做出了一點點探索而已,為了達到公眾期待的自動駕駛,需要做的還有太多太多,我這邊想提及幾點比較重要的技術方面的不足:
1.受限于成本、法律等等障礙,現在沒有團隊可以在真實場景中做類似的實驗,更不要提冒著損壞大量的車輛乃至于造成道路上安全事故的風險進行完整的基于探索的策略開發了,所以我們都只能在模擬環境下進行,而這就對模擬環境的真實性提出了很高要求。在如今的物理、數值計算、圖形學等領域的發展狀態下,我們還不可能有一個和現實場景一模一樣的模擬環境,這就對開發策略在真實場景中的可用性帶來了一些隱患。如果我們之后有了更加真實的模擬器乃至于“元宇宙”,這個問題或許可以被緩解一些。
2.我們的方法還基于人手工的損失函數的設計,這個問題也是現在的模型預測控制的一個幾乎共有的問題,這個損失函數設計的好壞類似于強化學習中的獎勵函數(reward function)的好壞一樣,都會對方法的效果產生很大的影響,但是因為設計開發者自身的知識、場景狀態簡化的可行性等,都不可能是最完美的,所以我們希望這個領域可以有一個更好的“適應性”(adpative)或者自學習的損失/獎勵函數的方法出現,在不同的場景和需求下使用不同的約束函數。但是這又變成了一個雞生蛋還是蛋生雞的問題,現在來看還是非常的困難。
3.我們的論文中提出,因為其他車輛行為的隨意性,受控車輛面對的實際上是“多假設未來”(multi-hypothesis future),也就是說從現在的時間點出發,即使受控車輛一直采取一樣的行動,未來的整個道路情況都依舊是不確定的。為了解決這個問題,我們設計去預測未來的的狀態分布,而不是單一可能。但是從根本上說,這種方法受限于模型的遺忘和從有限數據采樣預測分布的困難等問題,做的還是不夠好的,需要進一步的改進。
做研究的過程某種程度上也是個不斷自我否定的過程,逐步發現自己做的東西的不足,但在這里我還是對自己寬容一些吧,就先只說這三點吧。
澎湃新聞:這個項目過程中遇到的最大挑戰是什么?
曹金坤:挑戰還是蠻多的,首先是我們的方法還是會利用一些黑箱吧,很多時候一個模型的效果不好,我們會比較難知道怎么去定位,需要一些嘗試。然后是一些工程上的問題,無論是CARLA還是GTA V,用起來都需要一些學習成本的。最后是時間問題,我做這個項目的時候是在加州大學伯克利分校做訪問,因為我們的方法是完全在線的,收集數據和訓練模型都需要實時的去做,我們經常一次嘗試就需要訓練四五天然后才能知道結果,這樣的周期還是很長的,等待過程有點煎熬。
澎湃新聞:接下來的研究計劃是什么呢?
曹金坤:我現在在新的學校讀博了,也有一些新的任務,和計算機視覺以及自動駕駛還是有關的,但是因為研究組的方向問題,在這個項目上暫時沒有進一步的計劃了。我前面也說了很多的缺陷可以作為future works的起點,或許會有別的研究者繼續做相關的工作吧。
澎湃新聞:您作為相關專業領域的研究人員,覺得商用的完全的自動駕駛離我們還有多遠?
曹金坤:這個問題很好,我常常有一個看法是,很多問題,特別是技術問題,為了讓公眾了解,方便傳播,往往會被過分的簡化。比如“商用的完全的自動駕駛”怎么去定義它呢?我們現在常說L1-L5,但是這個也是有問題的。如果我們討論的是科幻中那種完全移除了駕駛座,道路上100%都是自動駕駛車輛在駕駛的話,我覺得技術上可能只需要10年吧,事故率就可以低于現在的人駕駛的事故率了,但是考慮到相關的法律、就業等問題,我覺得這個周期會長的多。另外,如果這些車輛可以互相的分享信息,他們不是所謂的獨立智能體的話,這個事情在技術上會更快一些。但是,如果不是100%的自動駕駛車輛,而是人和自動駕駛車輛混合的話,問題就變得復雜的多了,在法律上和技術上都是如此,我很難去預測這個事情了,我覺得也不可能有人可以預測。
澎湃新聞:您提到了在向公眾傳播技術問題時候對問題簡化的帶來的問題,我們作為媒體從業者對這點非常的感興趣,可以展開說說么?
曹金坤:實際上就是一個嚴謹性和傳播性的取舍了。現在人工智能很火,很多的公眾號都是請我們這些從業者去寫論文都難免會有問題,這是因為技術問題的描述本來往往是需要很長的前綴的,而在面向公眾的傳播載體中,一般很難這么做,畢竟一個句子太長,讀兩遍讀不懂,讀者就不看了。我們這些博士是因為不讀不行,不然我們也不愿意讀呀。
我舉個例子吧,關于最近的特斯拉放棄雷達這個事情,我看網上有人在討論“好不好”、“可行不可行”。但這個問題真的很難被如此簡單的討論,因為這和人們對于“自動駕駛有多好”的期待有關。如果只是期待自動駕駛做到和人一樣的安全性,那當然是可行的,畢竟人的腦袋上也沒有長雷達。但是如果是期待在很多的場景下,比如大雨大雪等,自動駕駛可以做人做不到的事情,那么特斯拉可以說是基本放棄了這個野心了。所以在傳播和討論的時候,有時候把這些前提說清楚還是蠻重要的,而如何怎么簡潔準確地說清楚這個事情,讓技術類的文章相對準確又相對易讀,就是媒體的工作了。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

