- +1
國(guó)內(nèi)數(shù)十位NLP大佬合作,綜述預(yù)訓(xùn)練模型的過(guò)去、現(xiàn)在與未來(lái)
機(jī)器之心報(bào)道
機(jī)器之心編輯部
來(lái)自清華大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)系、中國(guó)人民大學(xué)信息學(xué)院等機(jī)構(gòu)的多位學(xué)者深入地研究了預(yù)訓(xùn)練模型的歷史和發(fā)展趨勢(shì),并在這篇綜述論文中從技術(shù)的角度理清了預(yù)訓(xùn)練的來(lái)龍去脈。
BERT 、GPT 等大規(guī)模預(yù)訓(xùn)練模型(PTM)近年來(lái)取得了巨大成功,成為人工智能領(lǐng)域的一個(gè)里程碑。由于復(fù)雜的預(yù)訓(xùn)練目標(biāo)和巨大的模型參數(shù),大規(guī)模 PTM 可以有效地從大量標(biāo)記和未標(biāo)記的數(shù)據(jù)中獲取知識(shí)。通過(guò)將知識(shí)存儲(chǔ)到巨大的參數(shù)中并對(duì)特定任務(wù)進(jìn)行微調(diào),巨大參數(shù)中隱式編碼的豐富知識(shí)可以使各種下游任務(wù)受益。現(xiàn)在 AI 社區(qū)的共識(shí)是采用 PTM 作為下游任務(wù)的主干,而不是從頭開始學(xué)習(xí)模型。
本文中,來(lái)自清華大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)系、中國(guó)人民大學(xué)信息學(xué)院等機(jī)構(gòu)的多位學(xué)者深入研究了預(yù)訓(xùn)練模型的歷史,特別是它與遷移學(xué)習(xí)和自監(jiān)督學(xué)習(xí)的特殊關(guān)系,揭示了 PTM 在 AI 發(fā)展圖譜中的重要地位。

論文地址:http://keg.cs.tsinghua.edu.cn/jietang/publications/AIOPEN21-Han-et-al-Pre-Trained%20Models-%20Past,%20Present%20and%20Future.pdf
清華大學(xué)教授、悟道項(xiàng)目負(fù)責(zé)人唐杰表示:這篇 40 多頁(yè)的預(yù)訓(xùn)練模型綜述基本上算是從技術(shù)上理清了預(yù)訓(xùn)練的來(lái)龍去脈。
此外,該研究還回顧了 PTM 的最新突破。這些突破得益于算力的激增和數(shù)據(jù)可用性的增加,目前正在向四個(gè)重要方向發(fā)展:設(shè)計(jì)有效的架構(gòu)、利用豐富的上下文、提高計(jì)算效率以及進(jìn)行解釋和理論分析。最后,該研究討論了關(guān)于 PTM 一系列有待解決的問題和研究方向,并且希望他們的觀點(diǎn)能夠?qū)?PTM 的未來(lái)研究起到啟發(fā)和推動(dòng)作用。
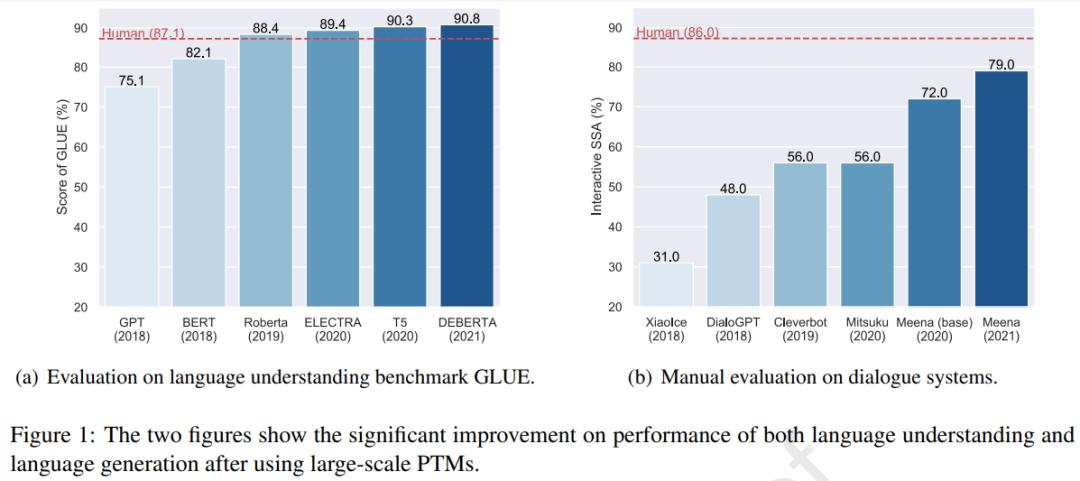
使用大規(guī)模 PTM 后語(yǔ)言理解和語(yǔ)言生成任務(wù)上性能出現(xiàn)了顯著提升。

圖(a)近年來(lái)語(yǔ)言模型相關(guān)的發(fā)表文章的數(shù)量,圖(b)近年來(lái)應(yīng)用 NLP PTM 后模型大小和數(shù)據(jù)大小的增長(zhǎng)趨勢(shì)。
背景介紹
最近 PTM 引起了研究人員的關(guān)注,但預(yù)訓(xùn)練并不是一種新穎的機(jī)器學(xué)習(xí)工具。事實(shí)上,預(yù)訓(xùn)練作為機(jī)器學(xué)習(xí)的一種范式已經(jīng)發(fā)展很多年了。本節(jié)介紹了 AI 領(lǐng)域中預(yù)訓(xùn)練的發(fā)展,從早期監(jiān)督預(yù)訓(xùn)練到當(dāng)前的自監(jiān)督預(yù)訓(xùn)練,了解這些有助于了解 PTM 的背景。
遷移學(xué)習(xí)和有監(jiān)督預(yù)訓(xùn)練
早期預(yù)訓(xùn)練的研究主要涉及遷移學(xué)習(xí)。遷移學(xué)習(xí)的研究很大程度上是因?yàn)槿藗兛梢砸揽恳郧皩W(xué)到的知識(shí)來(lái)解決新問題,甚至取得更好的結(jié)果。更準(zhǔn)確的說(shuō),遷移學(xué)習(xí)旨在從多個(gè)源任務(wù)中獲取重要知識(shí),然后將這些知識(shí)應(yīng)用到目標(biāo)任務(wù)中。
在遷移學(xué)習(xí)中,源任務(wù)和目標(biāo)任務(wù)可能具有完全不同的數(shù)據(jù)域和任務(wù)設(shè)置,但處理這些任務(wù)所需的知識(shí)是一致的。一般來(lái)說(shuō),在遷移學(xué)習(xí)中有兩種預(yù)訓(xùn)練方法被廣泛探索:特征遷移和參數(shù)遷移。
在一定程度上,表征遷移和參數(shù)遷移奠定了 PTM 的基礎(chǔ)。詞嵌入是在特征遷移框架下建立起來(lái)的,被廣泛應(yīng)用于 NLP 任務(wù)的輸入。
自監(jiān)督學(xué)習(xí)和自監(jiān)督預(yù)訓(xùn)練
如圖 4 所示,遷移學(xué)習(xí)可以分為四個(gè)子設(shè)置:歸納(inductive)遷移學(xué)習(xí)、transductive 遷移學(xué)習(xí)、自我(self-taught)學(xué)習(xí)和無(wú)監(jiān)督遷移學(xué)習(xí)。
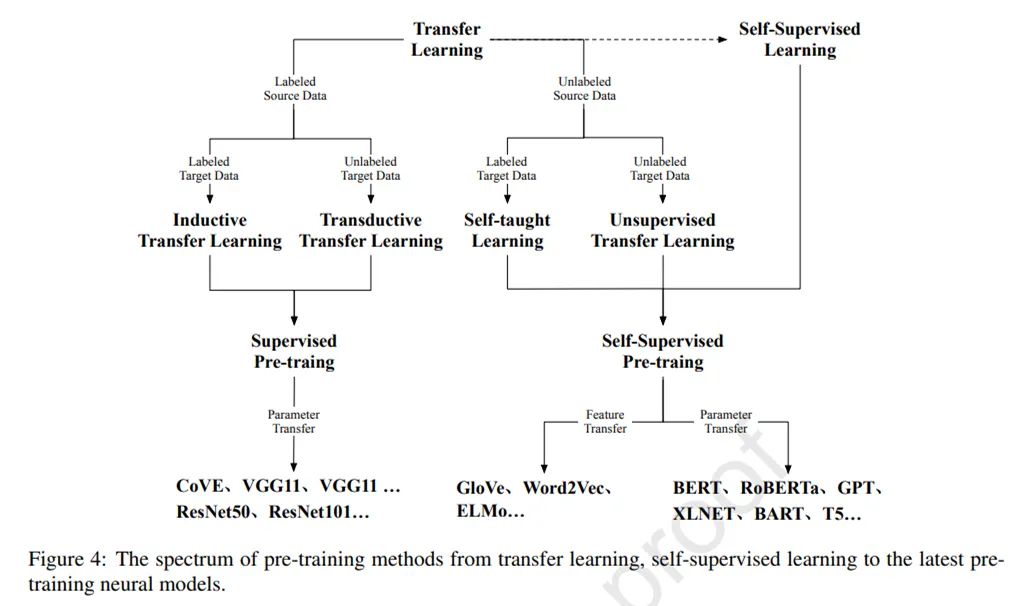
在這四種設(shè)置中,歸納和 transductive 設(shè)置是研究的核心,因?yàn)檫@兩種設(shè)置旨在將知識(shí)從有監(jiān)督的源任務(wù)遷移到目標(biāo)任務(wù)。
自監(jiān)督學(xué)習(xí)和無(wú)監(jiān)督學(xué)習(xí)在它們的設(shè)置上有許多相似之處。在一定程度上,自監(jiān)督學(xué)習(xí)可以看作是無(wú)監(jiān)督學(xué)習(xí)的一個(gè)分支,因?yàn)樗鼈兌歼m用于未標(biāo)記的數(shù)據(jù)。然而,無(wú)監(jiān)督學(xué)習(xí)主要側(cè)重于檢測(cè)數(shù)據(jù)模式(例如,聚類、社區(qū)發(fā)現(xiàn)和異常檢測(cè)),而自監(jiān)督學(xué)習(xí)仍處于監(jiān)督設(shè)置(例如分類和生成)的范式中。
自監(jiān)督學(xué)習(xí)的發(fā)展使得對(duì)大規(guī)模無(wú)監(jiān)督數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練成為可能。與作為深度學(xué)習(xí)時(shí)代 CV 基石的監(jiān)督預(yù)訓(xùn)練相比,自監(jiān)督預(yù)訓(xùn)練在 NLP 領(lǐng)域取得了巨大進(jìn)步。
隨著用于 NLP 任務(wù)的 PTM 的最新進(jìn)展,基于 Transformer 的 PTM 作為 NLP 任務(wù)的主干已成為流程標(biāo)準(zhǔn)。受 NLP 中自監(jiān)督學(xué)習(xí)和 Transformers 成功的啟發(fā),一些研究人員探索了自監(jiān)督學(xué)習(xí)和 Transformers 用于 CV 任務(wù)。這些初步努力表明,自監(jiān)督學(xué)習(xí)和 Transformer 可以勝過(guò)傳統(tǒng)的有監(jiān)督 CNN。
Transformer 和表征型 PTM
論文的第三部分從占主導(dǎo)地位的基本神經(jīng)架構(gòu) Transformer 開始,然后介紹了兩個(gè)具有里程碑意義的基于 Transformer 的 PTM,GPT 和 BERT,它們分別使用自回歸語(yǔ)言建模和自編碼語(yǔ)言建模作為預(yù)訓(xùn)練目標(biāo)。這部分的最后簡(jiǎn)要回顧了 GPT 和 BERT 之后的典型變體,以揭示 PTM 的最新發(fā)展。
Transformer
在 Transformer 之前,RNN 長(zhǎng)期以來(lái)一直是處理序列數(shù)據(jù)(尤其是自然語(yǔ)言)的典型神經(jīng)網(wǎng)絡(luò)。與 RNN 相比,Transformer 是一種編碼器 - 解碼器結(jié)構(gòu),它應(yīng)用了自注意力機(jī)制,可以并行建模輸入序列的所有詞之間的相關(guān)性。
在 Transformer 的編碼和解碼階段,Transformer 的自注意力機(jī)制計(jì)算所有輸入詞的表征。下圖 5 給出了一個(gè)示例,其中自注意力機(jī)制準(zhǔn)確地捕獲了「Jack」和「he」之間的參考關(guān)系,從而產(chǎn)生了最高的注意力分?jǐn)?shù)。

由于突出的性質(zhì),Transformer 逐漸成為自然語(yǔ)言理解和生成的標(biāo)準(zhǔn)神經(jīng)架構(gòu)。
GPT
GPT 是第一個(gè)將現(xiàn)代 Transformer 架構(gòu)和自監(jiān)督預(yù)訓(xùn)練目標(biāo)結(jié)合的模型。實(shí)驗(yàn)表明,GPT 在幾乎所有 NLP 任務(wù)上都取得了顯著的成功,包括自然語(yǔ)言推斷、問答等。
在 GPT 的預(yù)訓(xùn)練階段,每個(gè)詞的條件概率由 Transformer 建模。如下圖 6 所示,對(duì)于每個(gè)詞,GPT 通過(guò)對(duì)其前一個(gè)詞應(yīng)用多頭自注意力操作,再通過(guò)按位置的前饋層來(lái)計(jì)算其概率分布。
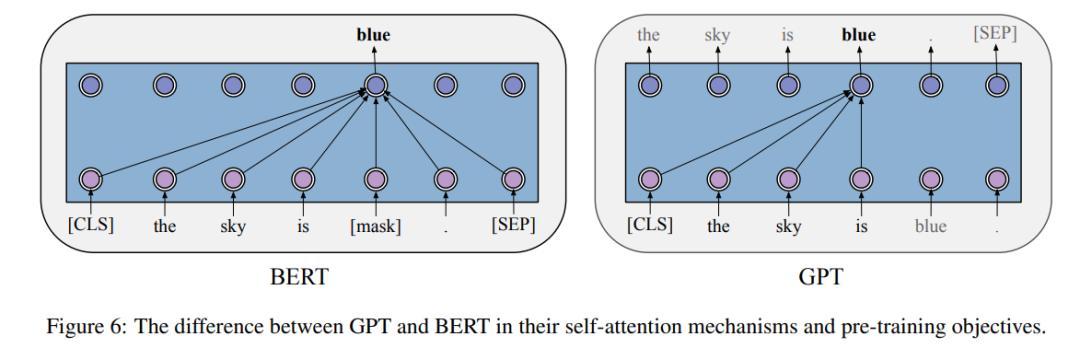
BERT
BERT 的出現(xiàn)也極大地推動(dòng)了 PTM 領(lǐng)域的發(fā)展。理論上,不同于 GPT ,BERT 使用雙向深度 Transformer 作為主要結(jié)構(gòu)。還有兩個(gè)獨(dú)立的階段可以使 BERT 適應(yīng)特定任務(wù),即預(yù)訓(xùn)練和微調(diào)(如下圖 7 所示)。
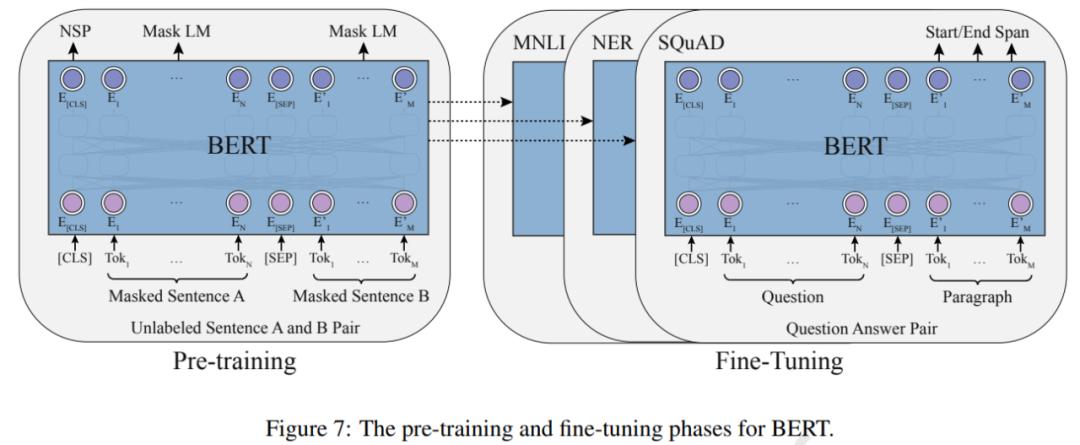
經(jīng)過(guò)預(yù)訓(xùn)練,BERT 可以獲得下游任務(wù)的穩(wěn)健參數(shù)。GPT 之后,BERT 在 17 個(gè)不同的 NLP 任務(wù)上進(jìn)一步取得了顯著的提升,包括 SQuAD(優(yōu)于人類的表現(xiàn))、GLUE(7.7% 的絕對(duì)提升)、MNLI(4.6% 的絕對(duì)提升)等。
GPT 和 BERT 之后
在 GPT 和 BERT 之后也出現(xiàn)了一些改進(jìn)模型,例如 RoBERTa 和 ALBERT。
如下圖 8 所示,為了更好地從未標(biāo)記的數(shù)據(jù)中獲取知識(shí),除了 RoBERTa 和 ALBERT 之外,近年來(lái)還提出了各種 PTM。一些工作改進(jìn)了模型架構(gòu)并探索了新的預(yù)訓(xùn)練任務(wù),例如 XLNet、MASS、SpanBERT 和 ELECTRA。

設(shè)計(jì)有效的架構(gòu)
在這一部分中,論文更深入地探究了 after-BERT PTM。基于 Transformer 的 PTM 的成功激發(fā)了一系列用于自然語(yǔ)言及其他序列建模的新架構(gòu)。一般來(lái)說(shuō),所有用于語(yǔ)言預(yù)訓(xùn)練的 after-BERT Transformer 架構(gòu)都可以被歸類為兩個(gè)動(dòng)機(jī):統(tǒng)一序列建模和認(rèn)知啟發(fā)架構(gòu)。此外,論文還在第三小節(jié)中簡(jiǎn)述了其他重要的 BERT 變體,它們主要側(cè)重于改進(jìn)自然語(yǔ)言理解。
統(tǒng)一序列建模
研究者發(fā)現(xiàn),一系列新架構(gòu)都在尋求將不同類型的語(yǔ)言任務(wù)與一個(gè) PTM 統(tǒng)一起來(lái)。論文中闡述了這一方面的發(fā)展,并探討了它們?yōu)樽匀徽Z(yǔ)言處理的統(tǒng)一帶來(lái)的靈感。
結(jié)合自回歸和自編碼建模,包括 XLNet (Yang 等, 2019) 和 MPNet (Song 等, 2020)。除了排列語(yǔ)言建模,還有一個(gè)方向是多任務(wù)訓(xùn)練,例如 UniLM (Dong 等, 2019)。最近,GLM(Du 等,2021)提出了一種更優(yōu)雅的方法來(lái)結(jié)合自回歸和自編碼。
有一些模型應(yīng)用泛化的編碼器 - 解碼器,包括 MASS (Song 等, 2019)、T5 (Raffel 等, 2020)、BART (Lewis 等, 2020a) 以及在典型 seq2seq 任務(wù)中指定的模型,例如 PEGASUS (Zhang 等,2020a)和 PALM(Bi 等,2020 )。
受認(rèn)知啟發(fā)的架構(gòu)
為了追求人類水平的智能,了解我們認(rèn)知功能的宏觀架構(gòu),包括決策、邏輯推理、反事實(shí)推理和工作記憶 (Baddeley, 1992) 至關(guān)重要。論文中概述了受認(rèn)知科學(xué)啟發(fā)的新嘗試,并重點(diǎn)闡述了可維持的工作記憶和可持續(xù)的長(zhǎng)期記憶。
可維持的工作記憶,包括基于 Transformer 的一些架構(gòu),例如 Transformer-XL (Dai 等, 2019)、CogQA (Ding 等, 2019) 和 CogLTX (Ding 等, 2020)。
可持續(xù)的長(zhǎng)期記憶。REALM (Guu 等, 2020) 是探索如何為變形金剛構(gòu)建可持續(xù)外部記憶的先驅(qū)。RAG (Lewis 等, 2020b) 將掩碼預(yù)訓(xùn)練擴(kuò)展到自回歸生成。
更多 PTM 變體
除了統(tǒng)一序列建模和構(gòu)建受認(rèn)知啟發(fā)的架構(gòu)以外,當(dāng)前大多數(shù)研究都集中在優(yōu)化 BERT 的架構(gòu)以提高語(yǔ)言模型在自然語(yǔ)言理解方面的性能。
一系列工作旨在改進(jìn)掩碼策略,可以將其視為某種數(shù)據(jù)增強(qiáng)(Gu 等, 2020),包括 SpanBERT (Joshi 等, 2020)、ERNIE (Sun 等, 2019b,c)、NEZHA (Wei 等, 2019) 和 Whole Word Masking (Cui 等, 2019)。
另一個(gè)有趣的做法是將掩碼預(yù)測(cè)目標(biāo)更改為更困難的目標(biāo),例如 ELECTRA(Clark 等,2020)。
利用多源數(shù)據(jù)
本節(jié)介紹了一些利用多源異構(gòu)數(shù)據(jù)的典型 PTM,包括多語(yǔ)言 PTM、多模態(tài) PTM 和知識(shí)增強(qiáng)型 PTM。
多語(yǔ)言預(yù)訓(xùn)練
在大規(guī)模英語(yǔ)語(yǔ)料庫(kù)上訓(xùn)練的語(yǔ)言模型在許多基準(zhǔn)測(cè)試中取得了巨大成功。然而,我們生活在一個(gè)多語(yǔ)言的世界中,并且由于所需的成本和數(shù)據(jù)量,為每種語(yǔ)言訓(xùn)練一個(gè)大型語(yǔ)言模型并不是一個(gè)最優(yōu)的解決方案。因此,訓(xùn)練一個(gè)模型來(lái)學(xué)習(xí)多語(yǔ)言表征而不是單語(yǔ)表征可能是更好的方法。
在 BERT 之前,一些研究人員已經(jīng)探索了多語(yǔ)言表征。學(xué)習(xí)多語(yǔ)言表征主要有兩種方法:一種是通過(guò)參數(shù)共享來(lái)學(xué)習(xí);另一種是學(xué)習(xí)與語(yǔ)言無(wú)關(guān)的約束。這兩種方式都使模型能夠應(yīng)用于多語(yǔ)言場(chǎng)景,但僅限于特定任務(wù)。
BERT 的出現(xiàn)表明,先對(duì)一般的自監(jiān)督任務(wù)進(jìn)行預(yù)訓(xùn)練,然后對(duì)特定的下游任務(wù)進(jìn)行微調(diào)的框架是可行的。這促使研究人員設(shè)計(jì)任務(wù)來(lái)預(yù)訓(xùn)練具有多功能的多語(yǔ)言模型。根據(jù)任務(wù)目標(biāo),多語(yǔ)言任務(wù)可分為理解任務(wù)和生成任務(wù)。
一些理解任務(wù)首先被用在非平行多語(yǔ)言語(yǔ)料庫(kù)上預(yù)訓(xùn)練多語(yǔ)言 PTM。然而,MMLM( multilingual masked language modeling )任務(wù)不能很好地利用平行語(yǔ)料庫(kù)。
除了 TLM( translation language modeling ),還有一些其他有效的方法可以從平行語(yǔ)料庫(kù)中學(xué)習(xí)多語(yǔ)言表征,如 Unicoder(Huang et al.,2019a)、ALM(Yang et al.,2020)、InfoXLM(Chi et al.,2020b)、HICTL(Wei et al.,2021)和 ERNIE-M(Ouyang et al.,2020)。
此外,該研究還廣泛探索了多語(yǔ)言 PTM 的生成模型,如 MASS(Song et al,2019 年)、mBART(Liu et al,2020c)。
多模態(tài)預(yù)訓(xùn)練
基于圖像 - 文本的 PTM,目前的解決方案是采用視覺 - 語(yǔ)言 BERT。ViLBERT(Lu et al,2019 年)是一個(gè)學(xué)習(xí)圖像和語(yǔ)言的 task-agnostic 聯(lián)合表征模型。它使用三個(gè)預(yù)訓(xùn)練任務(wù):MLM、句子 - 圖像對(duì)齊(SIA)和掩碼區(qū)域分類(MRC)。另一方面,VisualBERT(Li et al,2019 年)擴(kuò)展了 BERT 架構(gòu)。
一些多模態(tài) PTM 設(shè)計(jì)用于解決特定任務(wù),如 VQA。B2T2(Alberti et al,2019 年)是主要關(guān)注 VQA 的模型。LP(Zhou et al,2020a)專注于 VQA 和圖像字幕。此外,UNITER(Chen et al,2020e)學(xué)習(xí)兩種模式之間的統(tǒng)一表征。
OpenAI 的 DALLE (Ramesh et al., 2021) 、清華大學(xué)和 BAAI 的 CogView (Ding et al., 2021) 向條件零樣本圖像生成邁出了更大的一步。
最近,CLIP (Radford et al., 2021) 和 WenLan (Huo et al., 2021) 探索擴(kuò)大網(wǎng)絡(luò)規(guī)模數(shù)據(jù)以進(jìn)行 V&L 預(yù)訓(xùn)練并取得了巨大成功。
增強(qiáng)知識(shí)預(yù)訓(xùn)練
結(jié)構(gòu)化知識(shí)的典型形式是知識(shí)圖譜。許多工作試圖通過(guò)集成實(shí)體和關(guān)系嵌入或其與文本的對(duì)齊來(lái)增強(qiáng) PTM。
Wang et al.(2021) 基于維基數(shù)據(jù)實(shí)體描述的預(yù)訓(xùn)練模型,將語(yǔ)言模型損失和知識(shí)嵌入損失結(jié)合在一起以獲得知識(shí)增強(qiáng)表征。一個(gè)有趣的嘗試是 OAGBERT (Liu et al., 2021a),它在 OAG(open academic graph) (Zhang et al., 2019a) 中集成了異構(gòu)結(jié)構(gòu)知識(shí),并且涵蓋了 7 億個(gè)異構(gòu)實(shí)體和 20 億個(gè)關(guān)系。
與結(jié)構(gòu)化知識(shí)相比,非結(jié)構(gòu)化知識(shí)更完整,但噪聲也更大。
六至八章內(nèi)容概述
提升計(jì)算效率
研究者從以下三個(gè)方面介紹了如何提升計(jì)算效率:
系統(tǒng)級(jí)優(yōu)化,包括單設(shè)備優(yōu)化和多設(shè)備優(yōu)化;
高效預(yù)訓(xùn)練,包括高效訓(xùn)練方法和高效模型架構(gòu);
模型壓縮,包括參數(shù)共享、模型剪枝、知識(shí)蒸餾和模型量化。
解釋和理論分析
在介紹了 PTM 在各種 NLP 任務(wù)上的卓越性能之外,研究者還花篇幅解釋了 PTM 的行為,包括理解 PTM 的工作方式,揭示 PTM 捕獲的模式。他們探索了 PTM 的幾個(gè)重要屬性——知識(shí)、穩(wěn)健性和結(jié)構(gòu)稀疏性 / 模塊性,還回顧了 PTM 理論分析方面的開創(chuàng)性工作。
關(guān)于 PTM 的知識(shí),PTM 捕獲的隱式知識(shí)大致分為兩類,分別是語(yǔ)言知識(shí)和世界知識(shí)。關(guān)于 PTM 的穩(wěn)健性,當(dāng)研究人員為現(xiàn)實(shí)世界的應(yīng)用部署 PTM 時(shí),穩(wěn)健性已經(jīng)成為了一個(gè)嚴(yán)重的安全威脅。
未來(lái)方向
最后,研究者指出,在現(xiàn)有工作的基礎(chǔ)上,未來(lái) PTM 可以從以下幾個(gè)方面得到進(jìn)一步發(fā)展:
架構(gòu)和預(yù)訓(xùn)練方法
多語(yǔ)言和多模態(tài)預(yù)訓(xùn)練
計(jì)算效率
理論基礎(chǔ)
模型邊緣學(xué)習(xí)
認(rèn)知學(xué)習(xí)
新型應(yīng)用。
事實(shí)上,研究社區(qū)在以上幾個(gè)方向上都做了大量努力,也取得了一些最新的進(jìn)展。但應(yīng)看到,還有一些問題需要得到進(jìn)一步解決。
更多細(xì)節(jié)內(nèi)容請(qǐng)參考原論文。
? THE END
轉(zhuǎn)載請(qǐng)聯(lián)系本公眾號(hào)獲得授權(quán)
投稿或?qū)で髨?bào)道:content@jiqizhixin.com
原標(biāo)題:《國(guó)內(nèi)數(shù)十位NLP大佬合作,綜述預(yù)訓(xùn)練模型的過(guò)去、現(xiàn)在與未來(lái)》
本文為澎湃號(hào)作者或機(jī)構(gòu)在澎湃新聞上傳并發(fā)布,僅代表該作者或機(jī)構(gòu)觀點(diǎn),不代表澎湃新聞的觀點(diǎn)或立場(chǎng),澎湃新聞僅提供信息發(fā)布平臺(tái)。申請(qǐng)澎湃號(hào)請(qǐng)用電腦訪問http://renzheng.thepaper.cn。


- 澎湃新聞微博
- 澎湃新聞公眾號(hào)

- 澎湃新聞抖音號(hào)
- IP SHANGHAI
- SIXTH TONE
- 報(bào)料熱線: 021-962866
- 報(bào)料郵箱: news@thepaper.cn
滬公網(wǎng)安備31010602000299號(hào)
互聯(lián)網(wǎng)新聞信息服務(wù)許可證:31120170006
增值電信業(yè)務(wù)經(jīng)營(yíng)許可證:滬B2-2017116
? 2014-2025 上海東方報(bào)業(yè)有限公司

