- +1
一塊GPU頂數千個CPU內核,英偉達的這個強化學習利器技術細節終于公開了
機器之心報道
機器之心編輯部
很多機器人強化學習任務都面臨計算需求和仿真速度的瓶頸,而英偉達這個仿真環境可以將過去需要數千個 CPU 核參與訓練的任務移植到單個 GPU 上完成訓練。
強化學習已經成為機器學習中最有前途的研究領域之一,在解決復雜問題方面展現出了巨大的潛力。基于強化學習的系統在很多具有挑戰性的任務中展現出了超越人類的性能,比如圍棋、國際象棋、「星際爭霸」、DOTA 等等。
此外,基于強化學習的方法也為機器人應用帶來了希望,比如解魔方、通過模仿動物來學習運動等。
但直到現在,多數強化學習機器人研究者都不得不使用 CPU 和 GPU 的組合來運行強化學習系統。二者各司其職:CPU 用于模擬環境物理、計算獎勵和運行環境,而 GPU 用于在訓練和推理期間加速神經網絡模型,以及在需要時進行渲染。
然而,在為序列任務優化的 CPU 內核和提供大規模并行運算的 GPU 之間來回切換本質上是低效的,需要于訓練過程中在系統的不同部分之間進行多點數據傳輸。因此,機器人深度強化學習的可擴展性面臨兩個關鍵瓶頸:1)龐大的計算需求;2)有限的仿真速度。在擁有多個自由度的機器人學習長視野行為時,這個問題尤其具有挑戰性。
流行的物理引擎,如 MuJoCo、PyBullet、DART、Drake、V-Rep 等,需要大型 CPU 集群來解決具有挑戰性的強化學習任務,自然會面臨這些瓶頸。例如,OpenAI 2019 年推出了一個會玩魔方的機械手,為了訓練這個機械手,OpenAI 動用了大約 30,000 個 CPU 內核(920 臺 32 核計算機)。

在一個類似的手持立方體定位任務中,OpenAI 也用到了 6144 個 CPU 內核組成的 384 個系統集群,再加上 8 個 Volta V100 GPU,而且需要近 30 個小時的訓練才能達到最佳效果。這種手持立方體定位任務非常復雜,背后有著復雜的物理學、動力學原理和高維連續控制空間。

加速模擬和訓練的一種方法是使用硬件加速器。GPU 已經在計算機圖形學中取得了巨大的成功,自然也適用于高度并行的模擬。之前已經有研究采用了這種方法,并在 GPU 上運行仿真顯示了非常有前景的結果,證明使用 RL 可以極大地減少訓練時間,并解決龐大的計算資源需求。然而,一些瓶頸仍然沒有解決,即模擬是在 GPU 上,但物理狀態被復制回 CPU。在這種模式中,觀察和獎勵使用優化的 c++ 代碼計算,然后復制回 GPU。此外,只有簡化的基于物理的場景得到了訓練,而不是典型的機器人環境。
為了克服這些瓶頸,去年,英偉達發布了用于強化學習的物理模擬環境 Isaac Gym 預覽版。它可以借助 GPU 的并行計算能力,將過去需要數千個 CPU 核參與訓練的任務移植到單個 GPU 上完成訓練。
為什么 Isaac Gym 可以如此高效?昨天,英偉達機器人研究科學家(前 OpenAI 研究科學家)Ankur Handa 在推特上公布,他們已經發布了 Isaac Gym 的技術報告,里面詳細解釋了 Isaac Gym 的構建細節。
論文鏈接:https://arxiv.org/pdf/2108.10470.pdf
Isaac Gym 是一個端到端的高性能機器人仿真平臺,它運行一個端到端的 GPU 加速訓練 pipeline,使研究人員能夠克服上述限制,在連續控制任務中實現 2-3 個數量級的訓練加速。
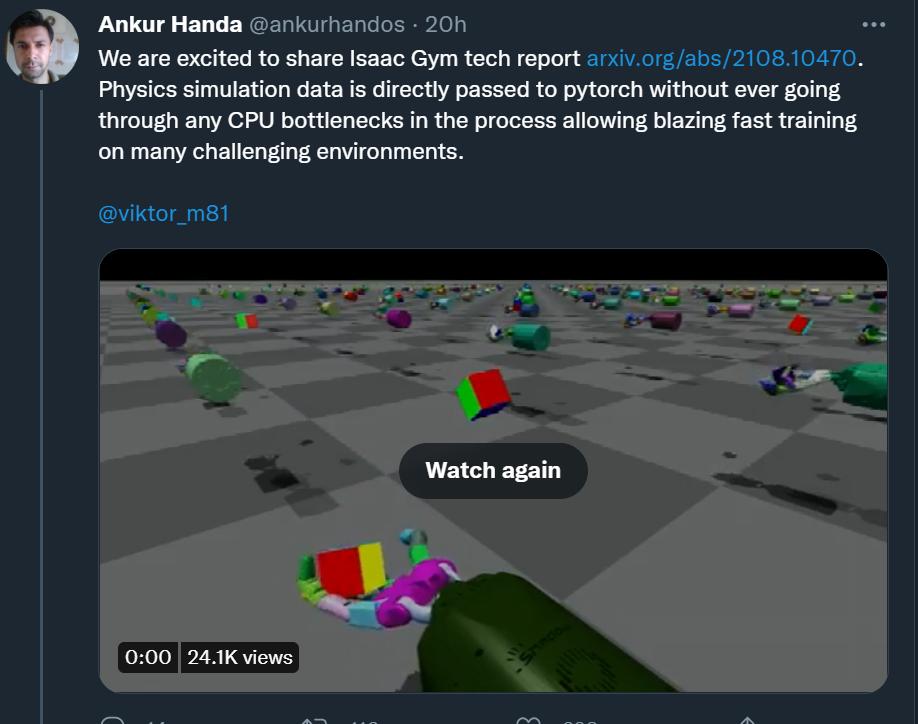
具體來說,Isaac Gym 利用 NVIDIA PhysX 提供了一個 GPU 加速的模擬后端,允許它以只有使用高度并行才能達到的速度收集機器人 RL 所需的經驗數據。它提供了一個基于 PyTorch 張量的 API,可以在 GPU 上本地訪問物理模擬的結果。觀測張量可以作為策略網絡的輸入,而產生的動作張量可以直接反饋到物理系統中。
借助端到端的方法,觀察、獎勵和動作的緩沖可以在整個學習過程中保留在 GPU 上,因此不需要從 CPU 讀取數據。這種設置使得一個 GPU 上可以同時處理數以萬計的環境,研究者可以輕松地在本地運行實驗。
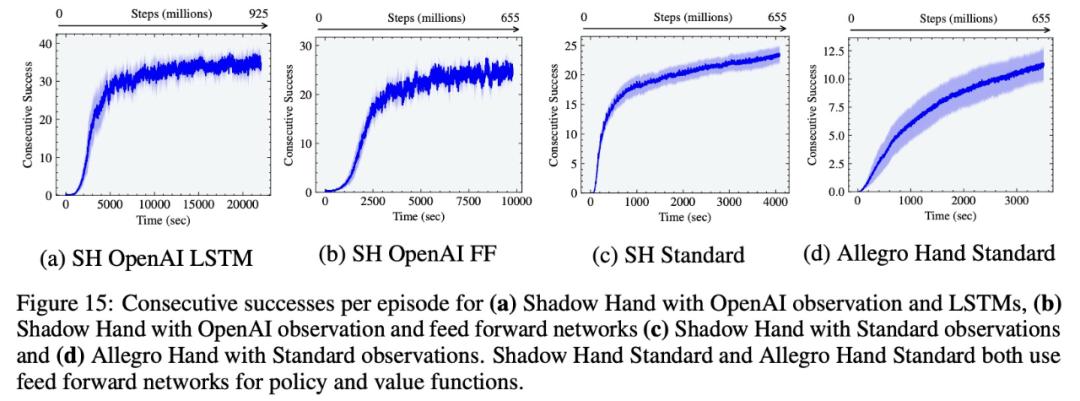
基于這一平臺,研究者復現了 OpenAI 的手持立方體定位任務。實驗表明,在 A100 上,Isaac Gym 可以實現與 OpenAI 相似的性能結果,即使用前饋連續成功 20 次,使用 LSTM 網絡連續成功 37 次,但分別只用了 1 小時和 6 小時左右。相比之下,之前 OpenAI 的研究分別需要 30 個小時和 17 個小時。

此外,研究者還在其他多個機器人任務上進行了實驗,Isaac Gym 都實現了明顯的加速。

以下是報告細節節選。
端到端 GPU 強化學習
Isaac Gym 通過利用英偉達的 PhysX GPU 加速模擬引擎實現了這些結果,使其能夠收集機器人 RL 所需的經驗數據。除了快速物理模擬以外,Isaac Gym 還支持在 GPU 上進行觀察和獎勵計算,從而避免嚴重的性能瓶頸,特別是消除了 GPU 與 CPU 之間昂貴的數據傳輸。通過這種方式實施,Isaac Gym 實現了完整的端到端 GPU 強化學習 pipeline。
Isaac Gym 提供了一個簡單的 API,用于創建包括機器人和物體場景,支持從常見的 URDF(Unified Robot Description Format)和 MJCF 文件格式加載數據。每個環境都可以根據需要進行多次復制,同時保留復制之間的變化能力(例如通過域隨機化)。該環境可以同時并行模擬,而不需要與其他環境交互。
使用一個完全由 GPU 加速的仿真和訓練 pipeline 可以幫助降低研究阻礙,使得以前只能在大型 CPU 集群完成的任務,現在僅用一個 GPU 即可解決。Isaac Gym 還包括一個基本的近似策略優化 (PPO) 實現和一個簡單的 RL 任務系統,用戶可以根據需要替換為其他任務系統或 RL 算法。當示例使用的是 PyTorch 時,用戶也能夠通過定制與 TensorFlow 訓練庫集成。
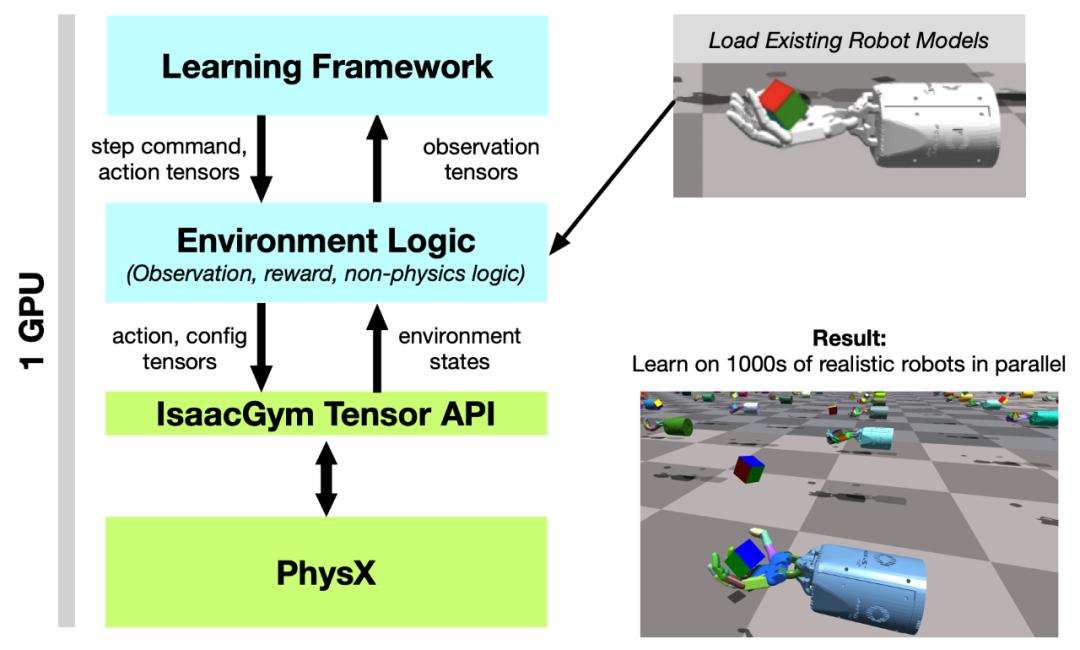
圖 2:系統概述。Tensor API 提供了一個 Python 代碼接口,可以直接在 GPU 上實現 PhysX 后端以及 get 和 set 模擬器狀態,在整個 RL 訓練 pipeline 中能實現 100 倍到 1000 倍的速度提升,同時提供高保真度的仿真,并且能夠與現有機器人模型連接。
這項研究的主要貢獻包括:
開發了用于機器人學習任務的高保真 GPU 加速的機器人模擬器;
Python 中的 Tensor API 將物理緩沖區封裝到 PyTorch 張量中,從而提供對物理緩沖區的直接訪問,而無需受到任何 CPU 限制;
實施多個高度復雜的機器人操作環境,這些環境可以在一個 GPU 上以每秒數十萬 step 的速度模擬;
在充滿挑戰的機器人環境中,使用 Isaac Gym 和 深度強化學習進行高性能訓練的結果。
實驗結果
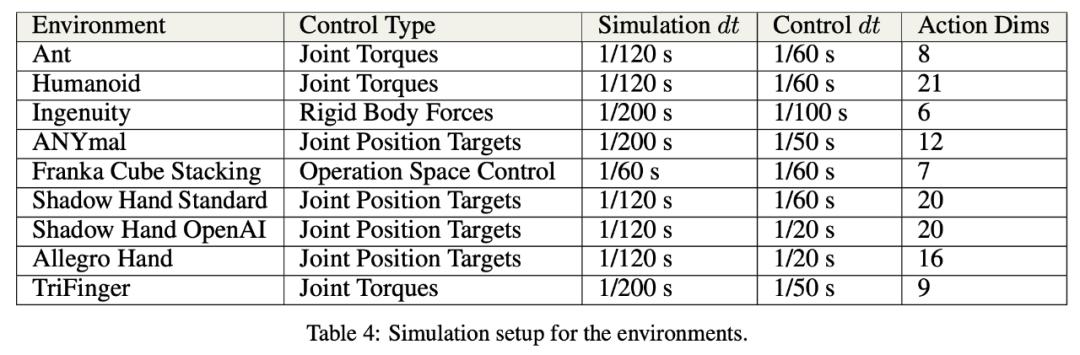
該研究在多種模擬環境中實現了顯著的訓練加速:在單個 NVIDIA A100 GPU 上,Ant 和 Humanoid 環境可以分別在 20 秒和 4 分鐘內實現高性能運動,而 ANYmal 的訓練也只需要不到 2 分鐘的時間,使用 AMP 的 Humanoid 角色動畫訓練需要 6 分鐘,使用 Shadow Hand 旋轉立方體需 35 分鐘。
研究者首先進行了「Ant 實驗」,在這個環境中,智能體被訓練在平坦的地面上運行。實驗發現,隨著智能體數量的增加,訓練時間如預期中一樣在減少。也就是說,環境數量由 256 個改變為 8192 個,增加了 5 個數量級,達到 7000 個獎勵數量級的訓練時間從 1000 秒 (約 16.6 分鐘) 減少到了 100 秒(約 1.6 分鐘)。但 Ant 在單個 GPU 上僅用 20 秒就可以達到 3000 次運動效果。
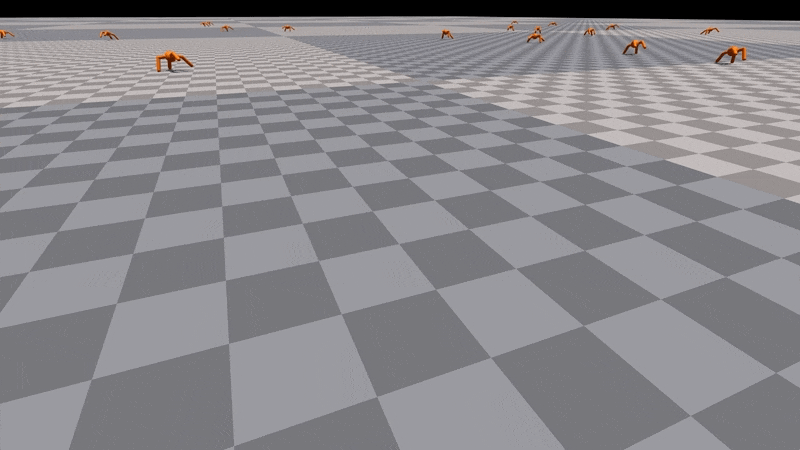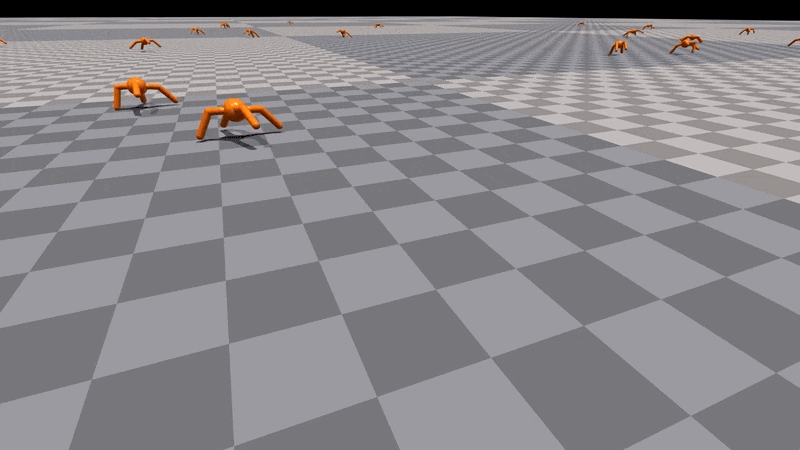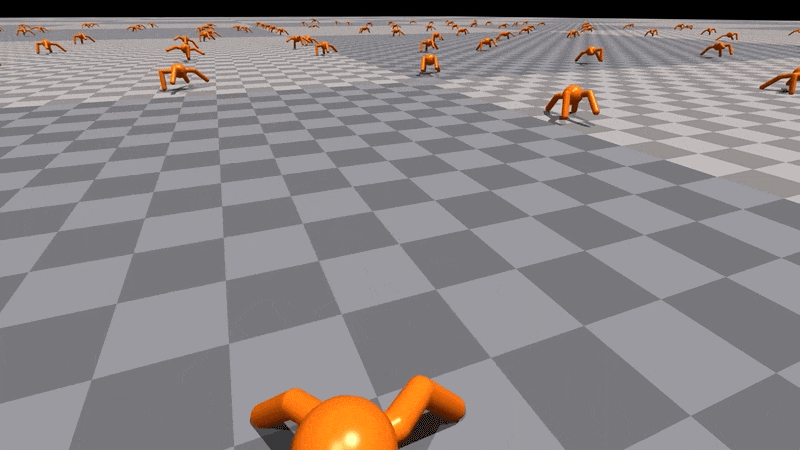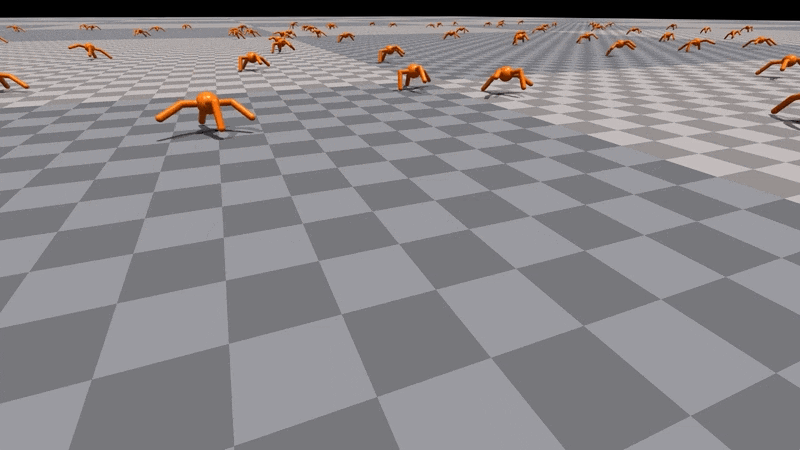
「Ant」是模擬最簡單的環境之一,每秒并行環境步驟的數量可能高達 700K。當環境數量從 8192 增加到 16384 時,由于水平長度減少,研究者沒能再觀測到增益。

研究者還為 ANYmal 開發了一個粗糙地面的運動任務,并通過將訓練好的策略轉移到實體機器人上來驗證了該方法的有效性。機器人學習在不平坦的地面、斜坡、樓梯和障礙物上行走,除了對平坦地形環境的觀察外,它還需要接收機器人周圍地形高度的測量數據。

該研究使用不對稱的 actor-critic 和域隨機化重現 OpenAI Shadow Hand 立方體的訓練設置。實驗結果表明,該研究在 A100 上,前饋連續 20 次成功和 LSTM 網絡連續 37 次成功,平均分別在大約 1 小時和 6 小時內獲得與當時 OpenAI 實驗結果相似的性能,成功容差為 0.4 rad。相比之下,使用傳統 RL 訓練設置,在 CPU 集群(384 個 CPU,每個 CPU 具有 16 個內核)和 8 個 NVIDIA V100 GPU、MuJoCo 的組合上,OpenAI 的工作分別需要 30 小時和 17 小時。
值得一提的是, OpenAI 僅顯示 1 個隨機種子的結果,相比之下,該研究中最好的種子在短短 2.5 小時內使用 LSTM 實現了 37 次連續成功。
該研究還在 ANYmal 和 TriFinger 上演示了模擬到現實的傳輸結果,這進一步展示了該研究的模擬器執行高保真接觸豐富操作任務的能力。
與吳恩達共話ML未來發展,2021亞馬遜云科技中國峰會可「玩」可「學」
2021亞馬遜云科技中國峰會「第二站」將于9月9日-9月14日全程在線上舉辦。對于AI開發者來說,9月14日舉辦的「人工智能和機器學習峰會」最值得關注。
當天上午,亞馬遜云科技人工智能與機器學習副總裁Swami Sivasubramanian 博士與 AI 領域著名學者、Landing AI 創始人吳恩達(Andrew Ng )博士展開一場「爐邊談話」。
不僅如此,「人工智能和機器學習峰會」還設置了四大分論壇,分別為「機器學習科學」、「機器學習的影響」、「無需依賴專業知識的機器學習實踐」和「機器學習如何落地」,從技術原理、實際場景中的應用落地以及對行業領域的影響等多個方面詳細闡述了機器學習的發展。
點擊閱讀原文,立即報名。

? THE END
轉載請聯系本公眾號獲得授權
投稿或尋求報道:content@jiqizhixin.com:,。視頻小程序贊,輕點兩下取消贊在看,輕點兩下取消在看
原標題:《一塊GPU頂數千個CPU內核,英偉達的這個強化學習利器技術細節終于公開了》
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

