- +11
達(dá)摩院首次將Pure Transformer模型引入目標(biāo)重識(shí)別,論文入選ICCV2021

原創(chuàng) Synced 機(jī)器之心
機(jī)器之心專欄
作者:羅浩
阿里達(dá)摩院的研究團(tuán)隊(duì)首次成功將pure transformer架構(gòu)應(yīng)用于目標(biāo)重識(shí)別(ReID)任務(wù),提出了TransReID框架,在6個(gè)數(shù)據(jù)集上都取得了超過SOTA CNN方法的性能。
Transformer是一種自注意力模型架構(gòu),2017年之后在NLP領(lǐng)域取得了很大的成功。2020年,谷歌提出pure transformer結(jié)構(gòu)ViT,在ImageNet分類任務(wù)上取得了和CNN可比的性能。之后大量ViT衍生的Pure Transformer架構(gòu)(下文中簡(jiǎn)稱為Transformer架構(gòu)/模型)在ImageNet上都取得了成功。此外,在檢測(cè)、跟蹤、分割等下游視覺任務(wù)上,pure transformer的架構(gòu)也不斷取得和CNN可比的性能,但是在更加細(xì)粒度的圖像檢索任務(wù)上目前還沒有將成功的工作。

TransReID論文地址:https://arxiv.org/pdf/2102.04378
TransReID代碼:https://github.com/heshuting555/TransReID
在這篇論文中,阿里達(dá)摩院的研究團(tuán)隊(duì)首次成功將pure transformer架構(gòu)應(yīng)用于目標(biāo)重識(shí)別(ReID)任務(wù),提出了TransReID框架,在6個(gè)數(shù)據(jù)集上都取得了超過SOTA CNN方法的性能。
研究背景
縱觀整個(gè)CNN-based ReID方法的發(fā)展,我們發(fā)現(xiàn)很多工作都關(guān)注兩個(gè)重要的點(diǎn):
1)挖掘圖片中的全局性信息。CNN網(wǎng)絡(luò)由于卷積核堆疊的原因,所以感受野存在一個(gè)高斯核的衰減。例如圖1所示,標(biāo)準(zhǔn)CNN的模型通常會(huì)關(guān)注于圖片中某一兩個(gè)比較有判別性的局部區(qū)域,而會(huì)忽視一些全局信息。為了解決這個(gè)問題,大量方法通過引入注意力機(jī)制來擴(kuò)大模型的有效感受野,從而得到更好的全局性。但是注意力機(jī)制僅僅只是緩解了CNN的這個(gè)問題,并不能徹底解決有效感受野高斯衰減的問題。但是Transformer中的自注意力模塊會(huì)使得每一個(gè)patch都和圖片中的patch都計(jì)算一個(gè)attention score,所以相比CNN模型在挖掘全局信息上有天然的優(yōu)勢(shì),并且multi-head也可以挖掘多個(gè)判別性區(qū)域。可以看到,圖1中Transformer-based的方法能夠挖掘多個(gè)具有判別性的局部區(qū)域。
2) 學(xué)習(xí)細(xì)節(jié)信息豐富的細(xì)粒度特征。CNN網(wǎng)絡(luò)里面存在下采樣操作來獲得平移不變性和擴(kuò)大感受野,但是同時(shí)也降低特征圖的分辨率,這會(huì)丟失圖像的一些細(xì)節(jié)信息。如圖2中的這對(duì)負(fù)樣本對(duì)(CNN識(shí)別錯(cuò)誤,Transformer識(shí)別正確),兩張圖片的外觀特征是非常相似的,但是從書包的細(xì)節(jié)可以看出,左邊書包側(cè)面有一個(gè)杯子,而右邊書包側(cè)面則沒有杯子,因此可以判斷是兩個(gè)ID。但是因此CNN的下采樣操作,在網(wǎng)絡(luò)最后輸出的特征圖上已經(jīng)看不清杯子這個(gè)細(xì)節(jié)了。但是Transformer沒有下采樣操作,因此特征圖能夠比較好地保留細(xì)節(jié)信息,從而識(shí)別目標(biāo)。

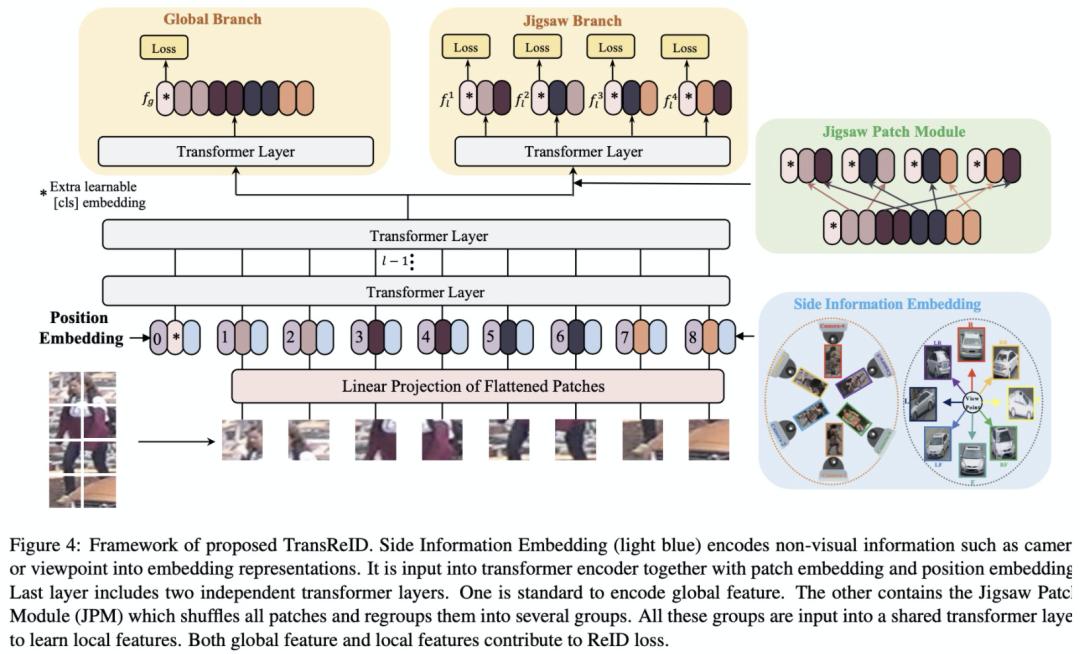
綜上所述,Transformer結(jié)構(gòu)是非常適合ReID任務(wù)的,但是僅僅用Transformer替換掉CNN backbone并沒有充分利用Transformer的特性。本文提出了首個(gè)pure transformer的ReID框架TransReID,包含JPM和SIE兩個(gè)新的模塊。之前的ReID工作顯示將圖片進(jìn)行切塊得到若干個(gè)part,然后對(duì)每個(gè)part提取local特征能夠提升性能。我們借鑒了這個(gè)設(shè)計(jì),將Transformer中的patch embedding分成若干個(gè)group,但是這個(gè)操作沒有充分利用Transformer的全局依賴性。因此我們?cè)O(shè)計(jì)了Jigsaw Patch Module (JPM),將patch embedding隨機(jī)打亂之后再切分group。Transformer非常擅長(zhǎng)encode不同模態(tài)的信息,而之前的ReID工作顯示相機(jī)和姿態(tài)信息是有利于ID的識(shí)別的,因此我們?cè)O(shè)計(jì)了Side Information Module (SIE) 來利用這些有益的信息。
TransReID
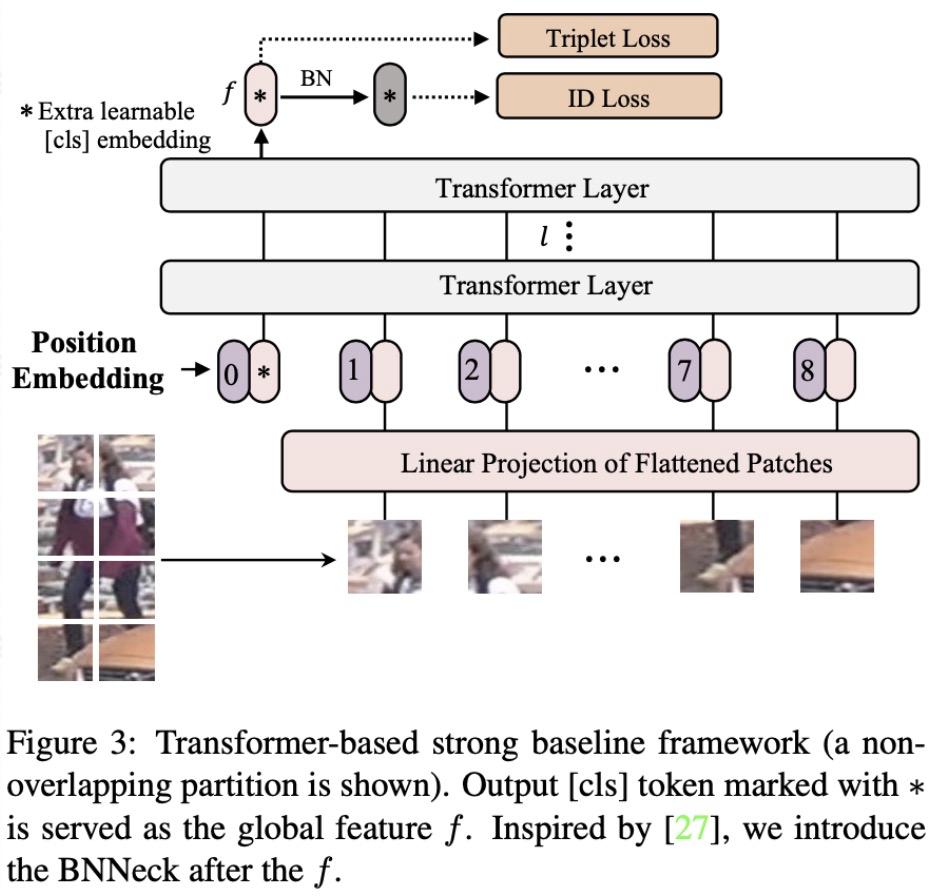
1、Transformer-based strong baseline
我們首先參考CNN的baseline BoT 設(shè)計(jì)Transformer-based strong baseline。如圖圖3所示,我們參考ViT將圖片分成N個(gè)patch,并引入一個(gè)額外的cls token共N+1個(gè)embedding。經(jīng)過Transformer layers之后,我們將cls token作為圖像的全局特征,之后經(jīng)過一個(gè)BNNeck結(jié)構(gòu)計(jì)算triplet loss和分類ID loss。
由于ImageNet預(yù)訓(xùn)練的ViT是使用224*224的圖像分辨率,而ReID通常使用的分辨率不會(huì)是224*224,這造成了position embedding的維度不一樣。因此,我們將position embedding按照空間位置進(jìn)行插值來加載預(yù)訓(xùn)練的position embedding參數(shù)。
此外,還有一個(gè)漲點(diǎn)的tricks是對(duì)圖像進(jìn)行patch分塊的時(shí)候可以讓相鄰的patch之間有一定的overlap。當(dāng)然這個(gè)操作會(huì)使得patch數(shù)目增加從而使得模型訓(xùn)練的資源消耗增加,但是性能也會(huì)有比較穩(wěn)定提升。
2、Jigsaw Patch Module
ReID任務(wù)經(jīng)常會(huì)遇到遮擋、不對(duì)齊這些問題,一般我們會(huì)采用細(xì)粒度的局部特征來處理這些問題,水平切塊就是非常常用的一種局部特征方法。JPM模塊借鑒水平切塊思想,將最后一層的patch embedding分成k個(gè)group (k=4),然后對(duì)于每個(gè)group進(jìn)行transformer encode得到N個(gè)cls token,每個(gè)cls token就相當(dāng)于PCB中的striped feature,計(jì)算一個(gè)loss。但是這么做有一個(gè)缺點(diǎn):每個(gè)group只包含了圖片中一個(gè)局部區(qū)域的信息,而transformer的特性是能夠挖掘全局關(guān)聯(lián)性。為了擴(kuò)大每個(gè)group的「視野」,我們將所有的patch embedding按照一定規(guī)則進(jìn)行打亂,然后再進(jìn)行分組。這樣每個(gè)group就可能包含來自圖片不同區(qū)域的patch,近似等效于每個(gè)group都有比較全局的「視野」。此外,打亂操作也可以看做是給網(wǎng)絡(luò)增加了一些擾動(dòng),使得網(wǎng)絡(luò)能夠?qū)W習(xí)到更加魯棒的特征。
具體打亂操作分為兩步:(1)將最后一層輸出的patch embedding去除0號(hào)位置的cls token可以得到N個(gè)patch embedding,之后將它們進(jìn)行循環(huán)平移m步;(2)第二步參照shuffle的group shuffle操作將N個(gè)patch的順序打亂得到新順序的N各patch embedding,之后將它們按照新順序分為k個(gè)group,每個(gè)group都學(xué)習(xí)一個(gè)cls token,最終concat所有cls token作為最終的feature。

2、Side Information Embeddings
ReID任務(wù)中相機(jī)、視角的差異會(huì)給圖像帶來一些外觀上的差異,所以不少工作關(guān)注怎么抑制這些bias。對(duì)于CNN框架,通常需要專門設(shè)計(jì)結(jié)構(gòu)來處理這個(gè)問題,例如設(shè)計(jì)loss、對(duì)數(shù)據(jù)進(jìn)行先驗(yàn)處理、改變模型結(jié)構(gòu)等等。這些設(shè)計(jì)通常比較定制化且比較復(fù)雜,推廣性并不強(qiáng)。而transformer則比較擅長(zhǎng)融合不同模態(tài)的信息,因此我們提出了SIE模塊來利用相機(jī)ID、視角等輔助信息。
與可學(xué)習(xí)的position embedding類似,我們使用了可學(xué)習(xí)的embedding來編碼相機(jī)ID和方向ID這些Side information,這個(gè)模塊成為Side Information Embedding (SIE)。假設(shè)總共有Nc個(gè)相機(jī)ID和Nv個(gè)方向ID,某張圖片的相機(jī)ID和方向ID分別是r和q,則他們最終的SIE編碼為:
最終,backbone的輸入為patch embeding、position embedding和SIE \mathcal{S}_{(C,V)}的加權(quán)之和。圖4展示了TransReID的完整框架,在ViT的基礎(chǔ)上增加了JPM和SIE模塊。
實(shí)驗(yàn)結(jié)果
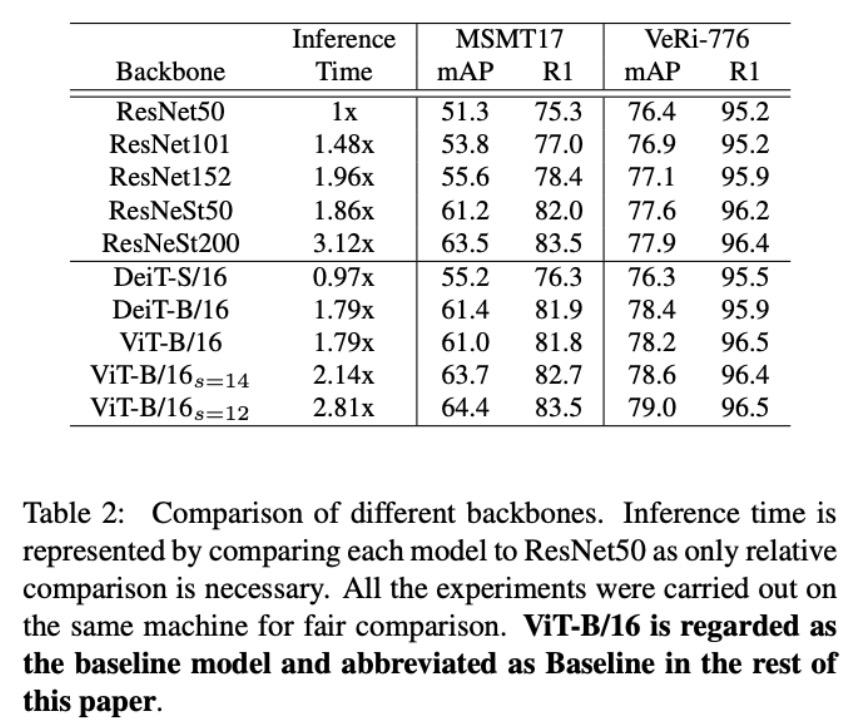
1、不同Backbone的對(duì)比
Table 2給出了不同Backbone的準(zhǔn)確度和推理時(shí)間的對(duì)比,我們將ResNet50作為baseline,同時(shí)我們給出了ViT和DeiT的結(jié)果。可以看到,DeiT-S/16在速度上與ResNet50是接近的,在準(zhǔn)確度上同樣也有可比的性能。當(dāng)我們使用更深的DeiT-B/16和DeiT-V/16時(shí),同樣和ResNest50取得了相似的速度和準(zhǔn)確度。當(dāng)我們?cè)趐re-patch環(huán)節(jié)縮小conv的stride時(shí),patch的數(shù)目增加,速度下降,但是準(zhǔn)確度也會(huì)收獲穩(wěn)定的提升。
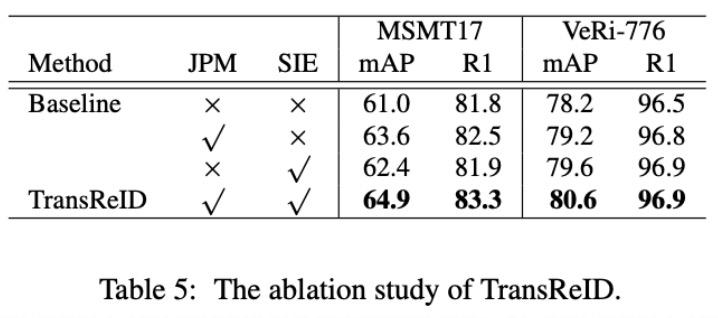
2、Ablation Study
詳細(xì)的消融實(shí)驗(yàn)可以看論文,這里只給出大模塊的消融實(shí)驗(yàn),我們以ViT-B/16作為baseline。從Table 5中的結(jié)果可以看出,JPM模塊和SIE模塊都是能穩(wěn)定帶來提升的,TransReID將這兩個(gè)模塊一起用還能進(jìn)一步提升結(jié)果。
3、和SOTA對(duì)比
Table 6給出了和SOTA方法對(duì)比的結(jié)果。可以看到,和CNN的方法相比,TransReID在六個(gè)ReID數(shù)據(jù)集上取得了更好的準(zhǔn)確度,這顯示了pure transformer架構(gòu)在圖像檢索任務(wù)上同樣適用。
一個(gè)有意思的地方是,在ImageNet上取得更好分?jǐn)?shù)的DeiT在下游的ReID任務(wù)上并沒有超過ViT。這是因?yàn)閂iT使用了更大的ImageNet22K做預(yù)訓(xùn)練,更大的預(yù)訓(xùn)練數(shù)據(jù)使得ViT有更好的遷移性。

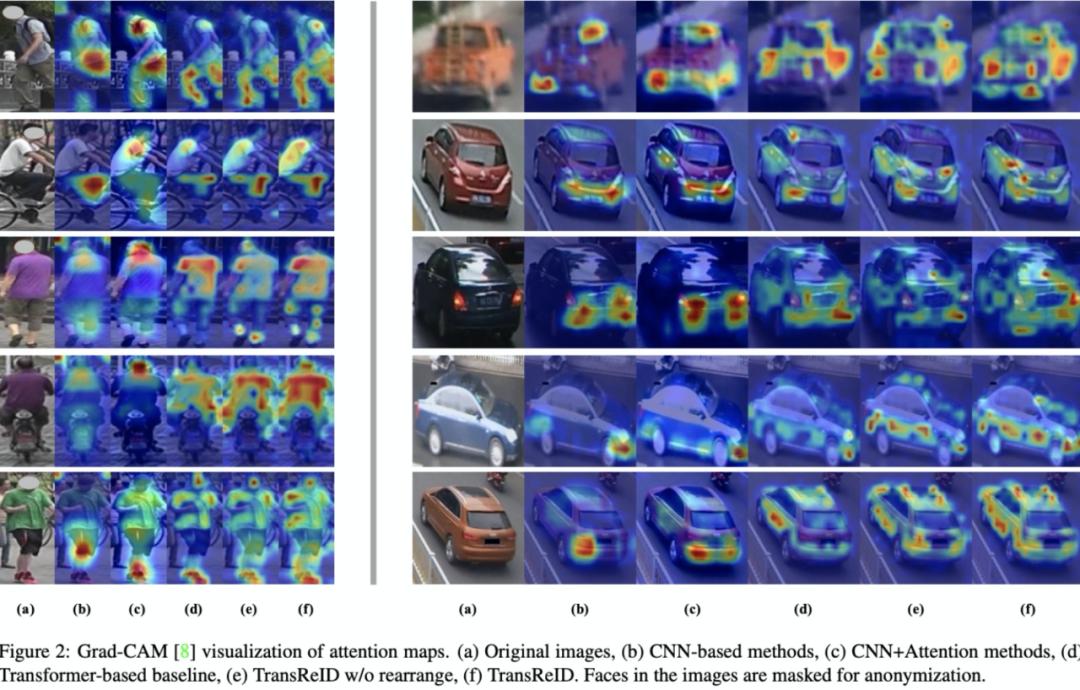
4、一些可視化
下圖給出了CNN和TransReID的注意力可視化結(jié)果,可以看出TransReID可以比CNN挖掘到更多判別性區(qū)域,同時(shí)有更好的全局性特征。
本文的論文作者包括兩位:
1.何淑婷,浙江大學(xué)博士生,阿里巴巴達(dá)摩院研究實(shí)習(xí)生,研究方向?yàn)槟繕?biāo)重識(shí)別,多目標(biāo)跟蹤等。曾在國(guó)內(nèi)外十幾項(xiàng)競(jìng)賽中取得前三的名次,其中包括六項(xiàng)冠軍。
2.羅浩,2020年博士畢業(yè)于浙江大學(xué),畢業(yè)后加入阿里巴巴達(dá)摩院,從事ReID方向的研究與技術(shù)落地工作。累計(jì)發(fā)表論文20余篇,Google scholar引用累計(jì)1000+次,代表作BagTricks Baseline開源代碼Star超過1.6K。曾經(jīng)獲得CVPR2021 AICITY Challenge、ECCV2020 VisDA Challenge, IJCAI2020 iQIYI iCartoonFace Challenge等國(guó)際比賽冠軍。博士期間創(chuàng)立浙大AI學(xué)生協(xié)會(huì)、在B站等平臺(tái)免費(fèi)開放《深度學(xué)習(xí)和目標(biāo)重識(shí)別》課程。
機(jī)器之心招人啦!
為進(jìn)一步生產(chǎn)更多的高質(zhì)量?jī)?nèi)容,提供更好數(shù)據(jù)產(chǎn)品及產(chǎn)業(yè)服務(wù),機(jī)器之心需要更多的小伙伴加入進(jìn)來,共同努力打造專業(yè)的人工智能信息服務(wù)平臺(tái)。
工作城市:北京市朝陽區(qū)酒仙橋 / 上海張江人工智能島
? THE END
轉(zhuǎn)載請(qǐng)聯(lián)系本公眾號(hào)獲得授權(quán)
投稿或?qū)で髨?bào)道:content@jiqizhixin.com
原標(biāo)題:《達(dá)摩院首次將Pure Transformer模型引入目標(biāo)重識(shí)別,論文入選ICCV 2021》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。







- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2025 上海东方报业有限公司

